Introduction
Vision Language Model은 시각정보와 언어정보를 동시에 처리하는 모델을 의미합니다. 인간이 눈으로 정보를 받아들여서 그 정보를 처리하는 것처럼, 모델도 이미지나 영상등의 시각적인 정보와, 택스트등의 언어정보를 동시에 입력받아 종합적으로 추론하는 모델을 의미합니다.
Vision Language Model은 단순히 언어만을 처리하는 LLM을 넘어, 다양한 입력정보를 처리하는 인간과 유사한 멀티모달 인공지능(Multimodal AI)을 구현할 수 있음을 보여주고 있습니다.
History
Vision Language Model은 크게 3단계로 나눌 수 있습니다.
연결의 시작 (2015년 이전) - ‘각각의 전문가를 이어 붙이다’
초창기 AI의 개발은 각각의 분야에 대하여 전문가였습니다. CNN은 시각적인 정보를 처리하는 것에 전문가였고, RNN/LSTM은 언어정보를 처리하는 것에 전문가였습니다. 이러한 전문가들을 이어 붙이는 것이 초기 AI의 개발이었습니다.
2014년, 구글의 연구자들이 “Show and Tell”이라는 모델을 통하여 두 전문가를 연결하는 방법을 제시했습니다.
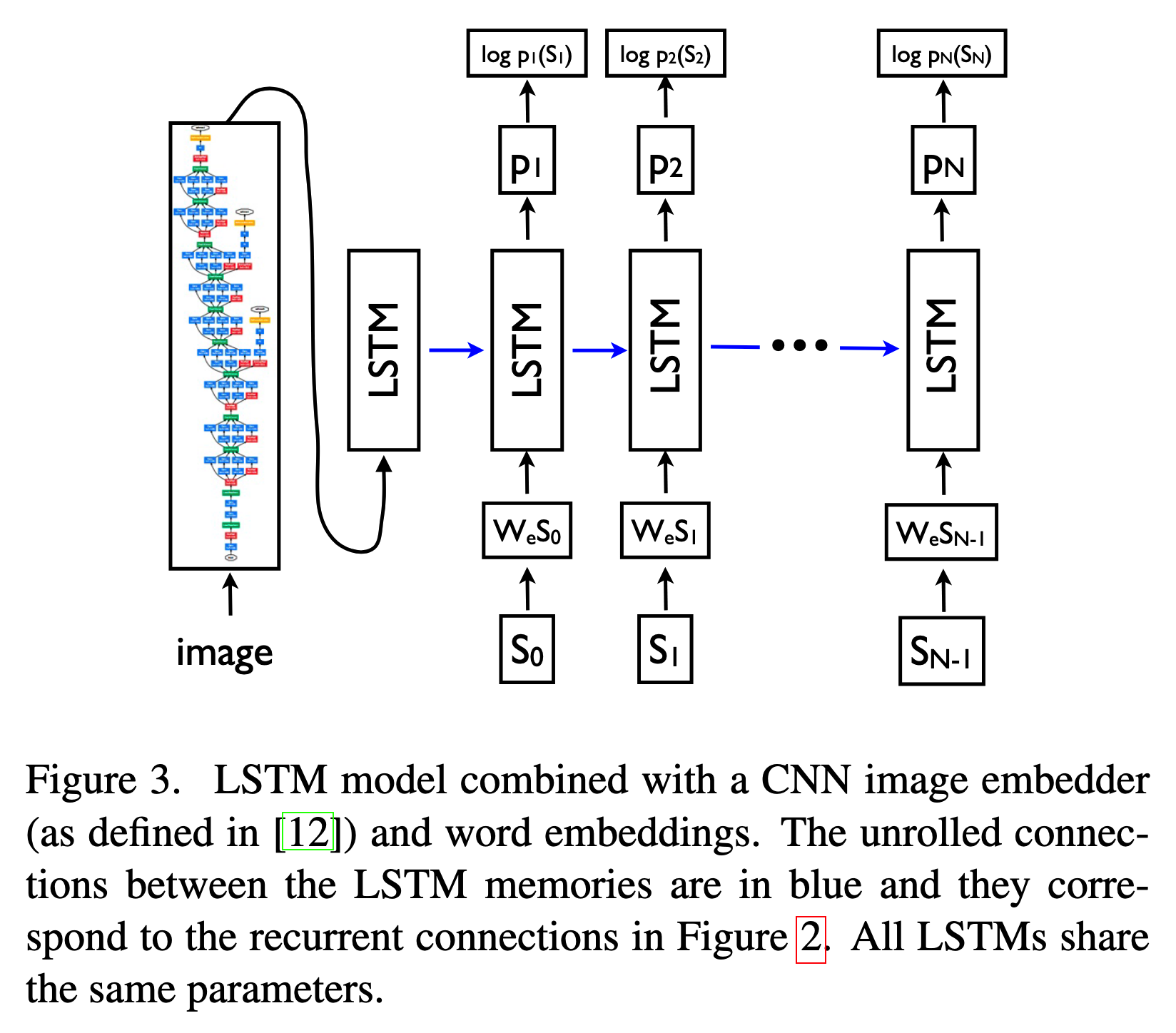
이미지를 잘 처리하는 Convolution Neural Network를 통해서 이미지를 vector로 변환시키고, 변환된 vector를 언어정보를 처리하는 RNN/LSTM에 초기 정보로 입력시켜 이를 통해서 이미지의 설명을 생성하는 모델로 만들었습니다.
이후 2015년, “Show, Attend and Tell”이라는 모델을 통하여 이미지의 정보를 attention을 기반으로 매 단어를 생성할때 마다 연속해서 처리하는 방법을 제시했습니다.
사전 훈련의 혁명 (2017년 ~ 2021년) - 스스로 세상을 배우는 거인의 탄생
2017년 OpenAI에서 GPT-1이라는 모델을 통하여 사전 훈련을 통해서 언어정보를 처리하는 모델을 제시했습니다.

이 모델의 주안점은 방대한 데이터를 통하여 사전학습을 하면 정답을 알려주지 않아도 모델이 정답을 도출할 수 있다는 것을 보여주었습니다. 다른 말로 하면 인터넷에 존재하는 모든 이미지와 택스트의 페어를 활용하여 학습을 시키는 것으로 이미지와 언어 사이의 연관성을 학습할 수 있는 것을 보여준 것입니다.
이러한 방식을 가장 잘 보여준 것이 2021년에 발표된 CLIP이라는 모델입니다.
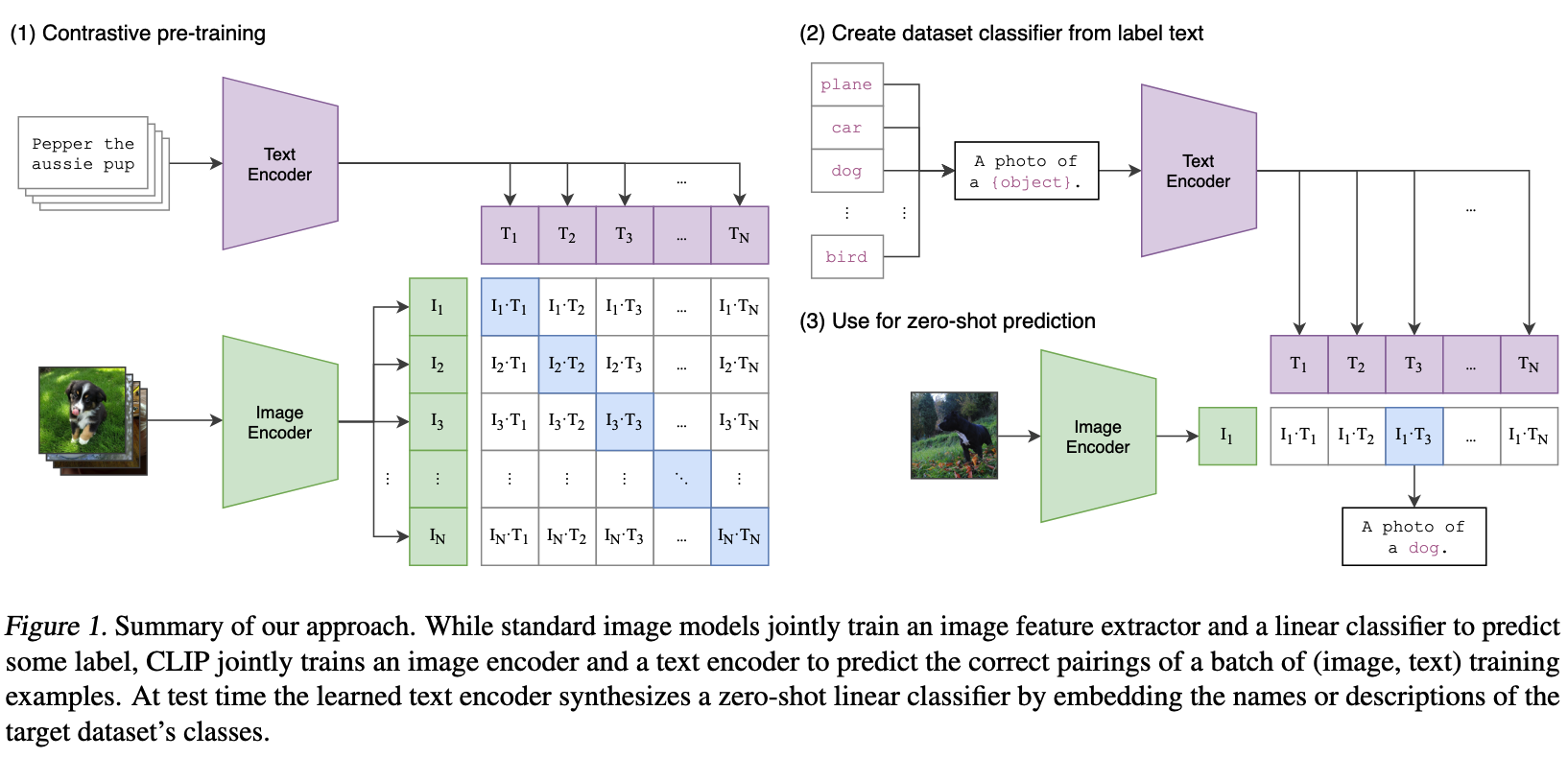
CLIP이라는 모델은 인터넷에서 가지고 온 정보를 기반으로 훈련을 하고 이미지와 택스트 사이의 연관성을 학습하였습니다. 이를 기반으로 Zero-shot 방식으로 Image Classification등의 Vision Task를 수행할 수 있습니다.
또한 DALL-E나 Stable Diffusion과 같은 생성형 모델등도 이러한 방식으로 훈련하여 택스트를 기반으로 이미지를 생성할 수 있게 되었습니다.
이 시기를 통하여 VLM이 특정한 작업을 수행하는 것만으로 학습을 하는 것이 아니라, 인터넷에 존재하는 모든 정보를 학습하여 더 보편적인 모델을 만들 수 있음을 보여주었습니다.
LLM과의 융합 (2022년 ~ 현재) - ‘세상을 보고 대화하다’
LLM의 크기가 급격하게 커지고 GPT-3를 활용한 Chat GPT가 나오면서, 세상은 또 다른 급격한 변화를 겪었습니다. LLM이 가지고 있는 보편적인 지식을 활용하는 방식을 VLM에 통합하려는 시도를 계속하였습니다.
이제는 모델이 이미지를 보고 설명하는 것을 넘어서, 이미지를 보고 사용자와 대화할 수 있는 형식으로 변화가 되었습니다.