1. Introduction
LLM은 기본적으로 이미 훈련된 모델을 사용한다. 하지만 원하는 목적에 따라서 모델을 fine-tuning하는 것이 중요하다. 크게 분류를 하자면 다음과 같은 형식들로 볼 수 있다.
- 프롬프팅 (모델을 훈련하지 않고 사용하는 방식)
- 파인튜닝 (모델을 훈련하는 방식)
- 정렬 (인간의 선호도에 맞추기)
2. 프롬프팅
프롬프팅은 LLM이 가지고 있는 잠재력을 끌어내면서 사용하는 것을 의미한다. 가장 처음 GPT에서 GPT2로 넘어갔을 때 훈련을 하지 않고도 다른 Task에 대하여 높은 성능을 보여주었다 모델의 크기가 점차 커지면서 GPT3에서도 비슷하게 높은 성능을 보여주면서 프롬프팅 만으로 좋은 성능을 낼 수 있는 방식이 없을까 생각을 한것이다.
2.1 In-Context Learning
In-Context Learning은 프롬프팅의 한 방법으로 모델에게 여러 정보들을 제공하여 모델이 원하는 결과를 제공하도록 하는 방법이다.
User: What is the capital of France?
Assistant: Paris
User: What is the capital of Germany?
Assistant: Berlin
User: What is the capital of Italy?
Assistant: Rome
User: What is the capital of Spain?
Assistant: Madrid
User: What is the capital of Portugal?
이런식으로 예시를 미리 제공하여 모델이 원하는 결과를 제공하도록 하는 방법이다.
이런 방식의 프롬프팅을 통해서 좋은 결과를 얻을 수 있지만 몇가지 단점이 있다. 여러 단계를 거쳐서 문제를 해결하는 수학 문제의 경우 예시를 제공하더라도 잘못된 답을 제공하는 경우가 존재한다.
이러한 문제를 해결하기 위해서 나온 것이 다음과 같은 Chain of Thought (CoT) 방식이다.
2.2 Chain of Thought (CoT)
Chain of Thought (CoT) 방식은 모델이 예시를 보고 문제를 해결하는 과정을 모델이 직접 표현하도록 하는 방식이다.
User: There is a box with 3 apples and 2 oranges. How many pieces of fruit are there?
Assistant: Let's think step by step.
1. There are 3 apples and 2 oranges.
2. To find the total number of pieces of fruit, we need to add the number of apples and oranges.
3. 3 apples + 2 oranges = 5 pieces of fruit.
So the answer is 5.
이렇게 이러한 예시를 직접적으로 주면서 어떤 과정의 생각이 일어났는지를 보여주고 그 결과를 순차적으로 생각을 하면서 문제를 푸는 방식을 의미한다. 이런 방법을 사용하면 모델을 새롭게 훈련하지 않고도 좋은 결과를 얻을 수 있다.
3. 파인튜닝
이 단계에서는 모델의 가중치 값을 직접적으로 수정하면서 모델을 학습시키는 것이다. 이때 모델을 학습시키는 방식에는 크게 두가지 방식이 있다.
- 모델의 가중치 값을 직접적으로 수정하면서 모델을 학습시키는 것
- Parameter-efficient fine-tuning (PEFT)
3.1 모델의 가중치 값을 직접적으로 수정하면서 모델을 학습시키는 것
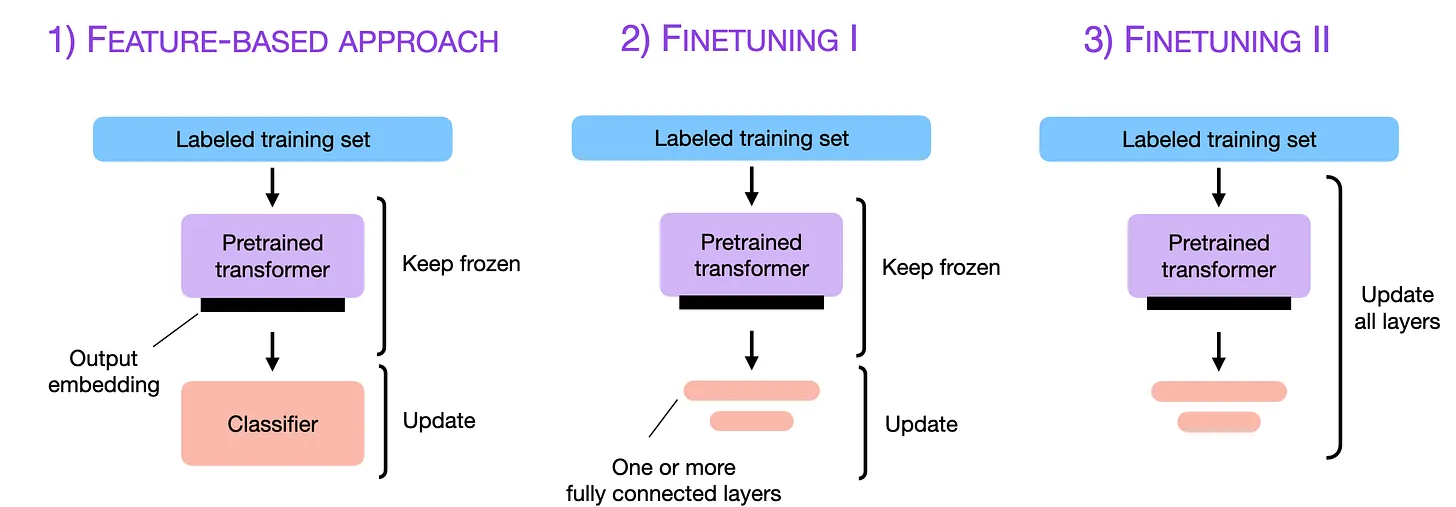
3.1.1 Feature-Based Approach (특징 기반 접근법)
LLM 시대 이전에 주로 사용되던 방식이다. 사전 훈련된 모델(e.g., BERT)을 텍스트의 의미를 담은 숫자 벡터(임베딩, 특징)를 추출하는 ‘특징 추출기’로만 사용한다.
- 작동 방식:
- 사전 훈련된 모델의 가중치를 완전히 고정(freeze)한다.
- 우리의 텍스트 데이터를 모델에 통과시켜 각 텍스트에 대한 특징 벡터를 얻는다
- 이 특징 벡터들을 입력으로 받는 별도의 작은 모델(e.g., 로지스틱 회귀, SVM, 작은 신경망)을 처음부터 학습시켜 원하는 과업(e.g., 분류)을 수행한다.
- 요약: 언어 모델은 ‘재료’를 만들 뿐, 실제 요리는 다른 ‘조리기구’가 담당하는 방식이다.
3.1.2 Finetuning I – Updating The Output Layers (출력층만 업데이트)
Feature-Based 방식보다 한 단계 발전한 형태이다.
- 작동 방식:
- 사전 훈련된 모델의 몸통(Body) 부분은 모두 고정한다.
- 모델의 맨 끝에 우리의 특정 과업을 위한 새로운 출력층(Output Layer/Head)을 추가한다. (e.g., 감성 분류를 위한 분류기 헤드)
- 오직 이 새로운 출력층의 파라미터만 학습시킨다.
- 요약: 기존 모델의 강력한 언어 이해 능력은 그대로 빌려오고, 최종 결정을 내리는 ‘머리’ 부분만 교체하여 학습하는 가벼운 파인튜닝이다.
3.1.3 Finetuning II – Updating All Layers (전체 파라미터 업데이트, Full Fine-Tuning)
현재 ‘파인튜닝’이라고 하면 일반적으로 이 방식을 의미합니다.
-
작동 방식: 사전 훈련된 모델의 모든 파라미터를 우리의 데이터셋으로 다시 학습시킨다.
-
장점: 모델 전체가 새로운 과업에 최적화되므로 최고의 성능을 기대할 수 있는다
-
단점: 막대한 컴퓨팅 자원이 필요하고, ‘치명적 망각(Catastrophic Forgetting)’ 문제가 발생할 수 있다
3.2 Parameter-efficient fine-tuning(PEFT)
PEFT는 Parameter-efficient fine-tuning의 약자로 한국어로 굳이 바꾸자면 ‘매개변수 효율적 파인튜닝’이라고 할 수 있다. LLM의 모델의 크기가 기하급수적으로 커지면서 모델의 모든 파라미터를 훈련시키는 것은 너무나 많은 비용, 시간, 데이터 등을 소모하게 되면서 모델의 극히 일부의 파라미터만 수정하거나 추가하여 훈련하는 기법들의 총칭이다.
3.2.1 PEFT의 주요 기법들
PEFT에는 여러 방법이 있지만, 현재 가장 널리 사용되고 중요한 기법은 다음과 같다
3.2.1.1 LoRA (Low-Rank Adaptation)
현재 PEFT의 사실상 표준(de-facto standard)으로 불리는 가장 인기 있는 기법이다.
-
핵심 아이디어: 거대한 가중치 행렬(Weight Matrix) W를 직접 수정하는 대신, 그 변화량 ΔW를 두 개의 작은 행렬 A와 B의 곱으로 근사(ΔW ≈ B x A)한다. 그리고 원본 W는 얼려둔 채, 이 작고 새로운 행렬 A와 B만을 학습시킨다.
-
장점: 매우 적은 파라미터만으로 높은 성능을 낼 수 있으며, 학습 후에는 A와 B를 기존 W에 합칠 수 있어 추론 시 추가적인 속도 저하가 없다
3.2.1.2 QLoRA (Quantized LoRA)
LoRA를 한 단계 더 발전시켜 자원 효율성을 극한으로 끌어올린 기법이다.
-
핵심 아이디어: 양자화(Quantization) 기술을 사용해 16/32비트의 큰 모델을 4비트의 저용량으로 압축하여 메모리에 올린 후, 그 상태에서 LoRA를 적용해 파인튜닝을 진행한다.
-
장점: 메모리 사용량을 획기적으로 줄여, 일반적인 단일 소비자용 GPU(예: RTX 4090)에서도 수백억 파라미터 모델의 파인튜닝을 가능하게 했다 LLM 튜닝의 대중화를 이끈 핵심 기술이다.
4. 정렬
4.1 Instruction Tuning
Instruction Tuning은 사용자의 다양한 지시사항(Instruction)을 이해하고 그에 맞게 적절한 결과물을 생성하도록 훈련시키는 특별한 파인튜닝(미세조정) 과정이다.
즉 pre-trained된 모델은 훈련된 정보들을 모두 가지고 있지만, 사용자가 원하는 대답을 제공하지 않는다. 이러한 모델에게 어떤 형식으로 답을 해주면 좋을지 알려주는 것이 Instruction Tuning이다.
4.1.1 Instuction Tuning이 중요한 이유
-
Zero-Shot 성능의 극대화: Instruction Tuning을 거친 모델은 처음 보는 생소한 과제에 대해서도 뛰어난 성능을 보인다. 사용자가 원하는 지시사항의 패턴들을 미리 학습하였기 때문에 새로운 지시사항에 유연하게 대처할 수 있게 된다.
-
사용자 의도와의 정렬(Alignment): 사전 훈련된 모델은 종종 사용자의 질문 의도와 다른 엉뚱한 답변을 내놓거나, 질문과 비슷한 형태의 문장을 계속 나열하기도 한다. Instruction Tuning은 모델이 사용자의 ‘의도’를 파악하고, 질문에 답하거나, 요약하거나, 번역하는 등 요구된 과업을 직접적으로 수행하도록 행동을 교정한다.
-
프롬프트 엔지니어링 부담 감소: 이 튜닝을 거치지 않은 모델을 잘 활용하려면 복잡하고 정교한 프롬프트(명령어)가 필요했다. 즉 사용자가 입력한 토근 앞에 가상의 토큰들을 추가하여 원했던 결과를 얻을 수 있었다. 하지만 Instruction Tuning을 통해 모델의 지시사항 이해 능력이 향상되면서, 사용자는 훨씬 단순하고 직관적인 명령만으로도 원하는 결과를 얻을 수 있게 되었다
4.1.2 Instruction Tuning 단점
하지만 이러한 방식에도 여러가지 문제점들이 있다.
- 모델을 훈련하는데 필요한 데이터가 많이 필요하다.
- 답이 정해져 있지 않은 문제에 대하여 훈련하기 어렵다.
- 우리가 원하는 답과 모델이 생성한 답이 다를 수 있다.
4.2 Reinforcement Learning with Human Feedback(RLHF)
RLHF는 사용자의 피드백을 바탕으로 모델을 훈련시키는 방식이다.
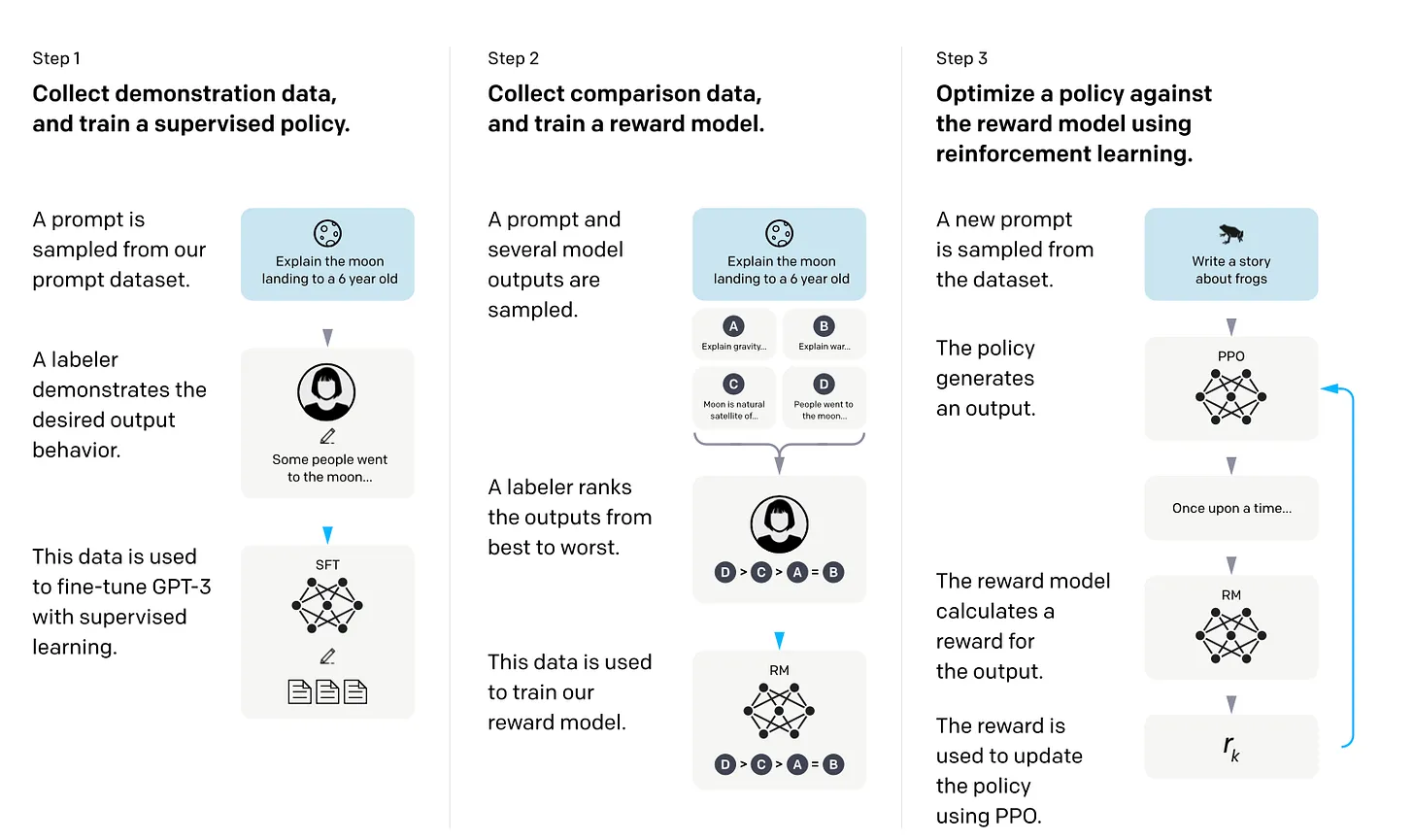
Instruction Tuning을 모두 마친 모델은 지시사항에 대하여 좋은 답변을 제공하지만, 사용자의 의도와 다른 답변을 제공하는 경우가 있다. 이러한 문제를 해결하기 위해서 RLHF를 사용하여 모델을 훈련시키는 방식이다.
User: 하늘이 푸른 이유를 알려줘?
예를 들어서 설명을 하면 다음과 같은 질문에 대하여 답을 요청했다고 하자. 이때 사용자가 누구냐에 따라서 원하는 답변의 깊이가 다를 수 있다.
어린아이가 질문을 했다고 하면 고차원적인 답변을 원하는 것보다 쉽게 이해를 할 수 있는 답변을 원할 것이다. 하지만 어느정도 나이가 있는 성인이 질문을 했을 때에는 조금은 더 자세한 정보, 고차원적인 정보, 용어들이 섞여 있어도 문제가 없을 것이다.
즉 주관적이라고 생각할 수 있는 부분을 훈련시키기 위해서 강화학습을 통해서 원하는 답변을 생성하도록 유도하는 것이다.
참고 자료
위 블로그 내용은 다음과 같은 블로그에서 어느정도 차용하였다