1. Introduction
2018년 6월, OpenAI의 Alec Radford 등이 발표한 “Improving Language Understanding by Generative Pre-Training” 논문은 자연어 처리(NLP) 분야에 혁신적인 변화를 가져온 기념비적인 연구입니다. 이 논문은 오늘날 널리 알려진 GPT(Generative Pre-trained Transformer) 모델의 첫 등장을 알렸으며, ‘생성적 사전 훈련(Generative Pre-training)’이라는 새로운 패러다임을 제시하며 이후 언어 모델 연구의 방향성을 완전히 바꾸어 놓았습니다.
이 논문이 발표되기 전까지 NLP 분야는 주로 특정 작업(task)에 특화된 모델을 처음부터 학습시키는 방식이 주를 이루었습니다. 예를 들어, 기계 번역 모델, 감성 분석 모델, 질문 응답 모델을 각각 별도의 데이터와 아키텍처로 구축해야 했습니다. 이는 많은 양의 레이블링된 데이터가 필요하고, 시간과 비용이 많이 소요되며, 모델의 범용성이 떨어진다는 한계를 가지고 있었습니다.
본 논문은 이러한 한계를 극복하기 위해, 대규모의 레이블 없는 텍스트 데이터(unlabeled text corpus)를 통해 언어 자체에 대한 깊은 이해를 먼저 학습하고(pre-training), 이를 기반으로 각 특정 작업에 맞게 미세하게 조정(fine-tuning)하는 2단계 접근법을 제안했습니다. 이 아이디어는 NLP 연구의 흐름을 ‘사전 훈련 및 파인 튜닝’ 시대로 이끄는 결정적인 계기가 되었습니다.
2. GPT-1
GPT-1의 핵심 방법론은 두 가지 단계로 나눌 수 있습니다.
2.1 비지도적 사전 학습 (Unsupervised Pre-training)
이 단계의 목표는 모델이 ‘언어’라는 것의 본질적인 통계적 패턴과 구조를 학습하도록 하는 것입니다. GPT는 이를 위해 ‘언어 모델링(Language Modeling)’ 이라는 단순하면서도 강력한 목표를 사용합니다. 구체적으로는, 주어진 단어 시퀀스(문맥)를 바탕으로 다음에 나타날 단어를 예측하는 과제를 수행합니다.
2.2 지도 파인 튜닝 (Supervised Fine-tuning)
사전 훈련을 통해 세상의 다양한 텍스트에 대한 ‘기본 지식’을 갖춘 모델은 이제 특정 NLP 작업을 수행할 준비가 되었습니다. 파인 튜닝 단계에서는 각 작업에 맞는 소량의 레이블링된 데이터셋(C)을 사용하여 모델을 추가로 학습시킵니다.
SFT를 통해서 학습하는 방식은 각각의 작업에 맞게 입력값과 출력값을 조절해주는 방식으로 알려준다.
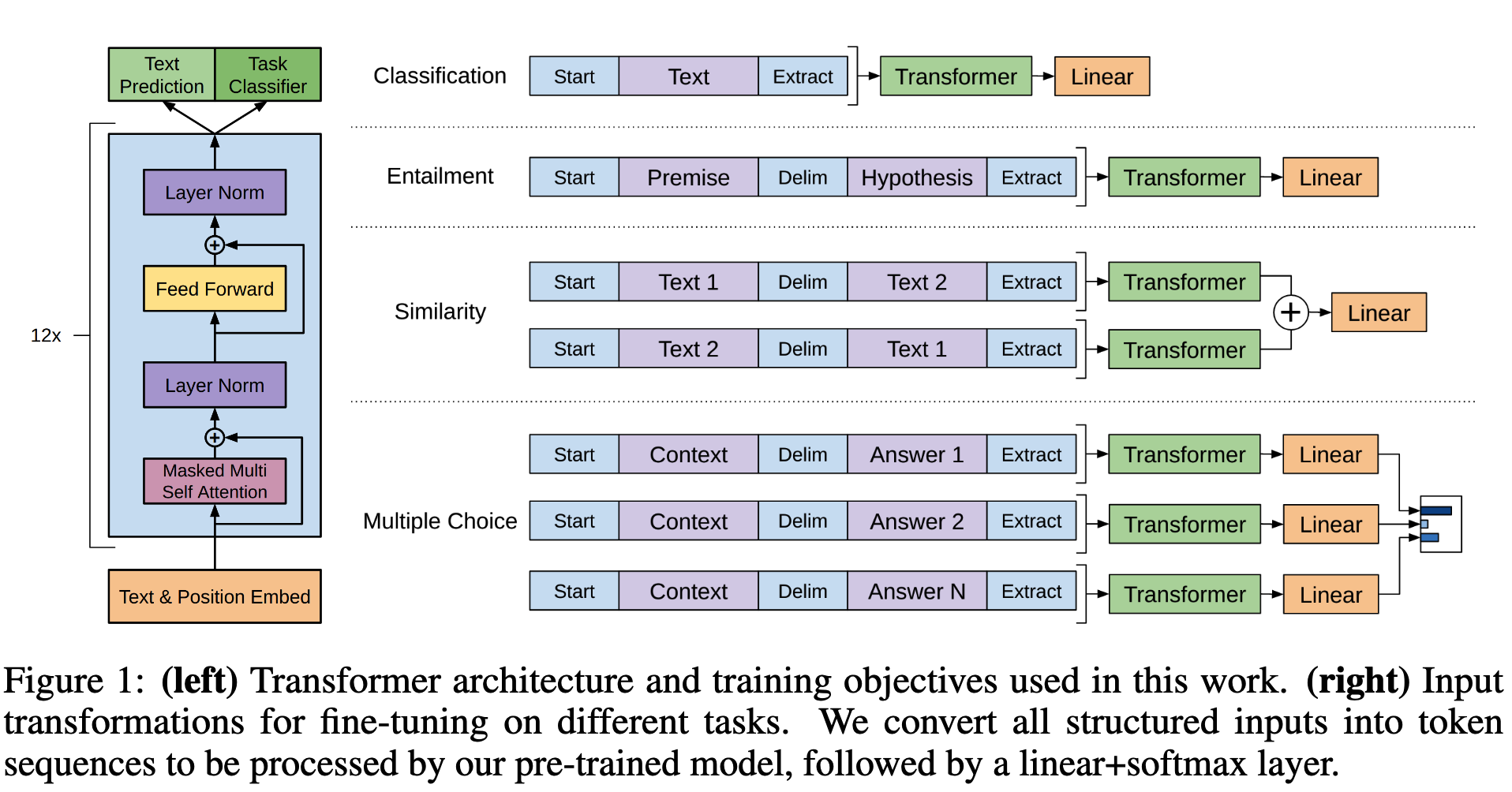
Classification Task
Classification Task는 입력값에 대하여 어떤 클래스에 속하는지 예측하는 작업이다. 예를 들어서 영화에 대한 리뷰가 주어졌을 때, 그 리뷰가 긍적적인 리뷰인지 아니면 부정적인 리뷰인지를 판단을 하는 작업을 말하는 것이다.
이 작업에서는 가장 간단한 방식으로 훈련을 할 수 있다. 그냥 기존의 방식과 동일하게 입력값을 주고 그 뒤에 간단한 Linear Layer를 통해서 그 값을 입력받는 것이다.
Textual Entailment
Textual Entailment는 전제 Premise를 통해 가설 Hypothesis의 참, 거짓을 밝히는 task 입니다. 예를 들어서 “A는 B라는 운동을 매일 하고 있다”라는 전제가 주어졌을 때, “A는 운동을 좋아한다.”라는 가설이 참인지 거짓인지를 판단하는 작업을 말하는 것이다.
이 작업에서는 전제와 가설을 연결해주는 방식으로 훈련을 할 수 있다. 이때 그 두 문장 사이에 Delimiter를 넣어주어서 두 문장 사이를 구분하게 해주는 방식으로 훈련을 한다.
Similarity Task
Similarity Task는 두 문장 사이의 유사도를 측정하는 작업이다. 예를 들어서 “대한민국의 수도는 서울특별시이다”라는 문장과 “한국의 수도는 서울이다”라는 문장 사이의 유사도를 측정하는 작업을 말하는 것이다.
이 작업에서는 Delimiter를 사용하여 A문장과 B문장을 구분한다. 또한 입력 순서를 바꿔서 두 문장 사이의 유사도를 측정하는 방식으로 훈련을 한다. 즉 [A, B]와 [B, A] 두 가지 입력 방식을 사용하여 Linear Layer를 통해서 두 문장 사이의 유사도를 측정하는 방식으로 훈련을 한다.
Question Answering and Commonsense Reasoning
Question Answering and Commonsense Reasoning는 질문에 대한 답변을 추론하는 작업이다. 예를 들어서 “대한민국의 수도는 어디인가?”라는 질문에 대한 답변을 추론하는 작업을 말하는 것이다.
이 작업에서는 질문과 답변을 Delimiter를 사용하여 구분하여 준다. 또한 하나의 질문에 대한 답변이 많은 경우 같은 질문에 대하여 여러가지 답변을 연결하여 훈련하는 것이다.
3. 모델 구조
논문에서 제시한 모델 구조는 다음과 같습니다.

GPT-1은 12개의 Transformer Decoder 레이어를 가지고 있습니다. 이때 기존의 Transformer의 Encoder 레이어는 사용하지 않고, Decoder 레이어만 사용하였습니다. 그와 함께 Encoder Layer와 Decoder Layer를 연결해주는 Cross Attension Layer를 제거하였습니다.
또한 Input이 들어가는 방식에서 기존의 sinusoidal position encoding을 사용하지 않고 learned position embedding을 사용하였습니다.
그리고 Transformer Layer에서 Activation을 기존의 ReLU 대신 GELU로 변경하였습니다.
4. 의의 및 영향: NLP 패러다임의 전환
“Improving Language Understanding by Generative Pre-Training” 논문은 다음과 같은 중요한 의의와 영향을 남겼습니다.
-
‘사전 훈련 및 파인 튜닝’ 패러다임의 정립: 이 논문 이후, NLP 연구는 대규모 비지도 데이터를 활용한 사전 훈련 모델을 기반으로 하는 방향으로 급격히 전환되었습니다. 이는 데이터 효율성과 모델 성능을 극적으로 끌어올렸습니다.
-
트랜스포머 디코더의 잠재력 입증: 트랜스포머 디코더 구조가 언어 생성뿐만 아니라, 다양한 자연어 이해(NLU) 작업에서도 강력한 성능을 보일 수 있음을 증명했습니다. 이는 이후 등장하는 GPT-2, GPT-3 등 후속 연구의 기반이 되었습니다.
-
범용 인공지능(AGI)으로의 가능성 제시: 단일 모델이 최소한의 수정만으로 다양한 종류의 언어 과제를 해결할 수 있다는 것을 보여줌으로써, 하나의 모델이 여러 지능적인 작업을 수행하는 범용 인공지능의 가능성을 엿보게 했습니다.
참고 자료
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
https://ffighting.net/deep-learning-paper-review/language-model/gpt-1/