Introduction
VLM에서 가장 중요한 모델이라고 하면 CLIP이라고 할 수 있다. CLIP은 기존의 Supervised 방식의 훈련에 대한 한계를 극복하기 위해서 나왔다. 기존의 이미지 인식 모델들은 이미지 데이터와 라벨을 이용하여 만들어졌다. 이러한 이미지 데이터와 라벨을 만드는 것에는 상당한 사람들의 노력이 필요했다.
이러한 노력을 줄이고, 인터넷에 존재하는 이미지와 택스트의 쌍을 활용하여 훈련하는 방식을 활용하였다. 방대한 데이터를 통하여 훈련하여, 다양한 이미지 분류 모델에서 추가적인 지도학습 없이 기존의 지도학습 모델과 비슷하거나 더 높은 성능을 보여주었다. 이 방식은 이후 다양한 VLM 모델에서 활용되었다.
기존 연구의 한계 : ImageNet 패러다임의 한계
기존에 뛰어난 Vision Model을 만들기 위해서는 ImageNet에 사전학습을 한 이후에 기타 다양한 작업에 대하여 훈련을 하는 것이 기존의 패러다임이었다. 하지만 이런 방식은 다양한 한계가 존재한다.
- 비용과 시간의 한계
- 기존의 방식에 따라서 훈련을 하기 위해서는 데이터셋을 만드는 것이 필요했다. 하지만 이러한 방식으로 사진을 수집하고 각 사진에 라벨을 붙이는 것은 사람이 해야할 일이고, 이로 인해서 많은 노력이 필요하다.
- 제한된 어휘
- ImageNet에 존재하는 이미지는 총 1000개의 클래스로 구성되어 있다. 총 1000개의 어휘로 제한되어 있기에 이미지가 강아지라는 것은 알아도 견종이 시바견인지, 허스키인지 정확하게 알 수는 없다.
- 취약한 일반화 성능
- 특정 데이터셋의 분포에 과적합되어, 실제 세상의 다양한 환경(e.g., 스케치, 만화, 다른 각도의 사진)에서는 성능이 급격히 저하되는 경향을 보였다.
OpenAI에서는 NLP를 훈련했던 방식을 참고하여, 인터넷에서 존재하는 이미지와 택스트의 쌍을 활용하는 방식을 제안했다. 이런 방식은 기존의 방식과 다르게 데이터셋을 만드는 방식이 아니라 이미 존재하는 데이터를 활용하는 방식으로 훈련을 하는 것이다.
CLIP의 핵심 아이디어: 대조 학습을 통한 시각-언어 정렬
CLIP이 가지고 있는 아이디어는 간단하다. 이미지와 택스트의 쌍을 활용하여 이미지와 택스트가 가지고 있는 embedding을 만든다. 이러한 embedding을 통하여 이미지의 embedding과 택스트의 embedding을 비교하여 같은 쌍은 유사하게 만들고 다른 쌍에 대하여 유사하지 않게 만드는 방식을 활용한 것이다.
두개의 인코더
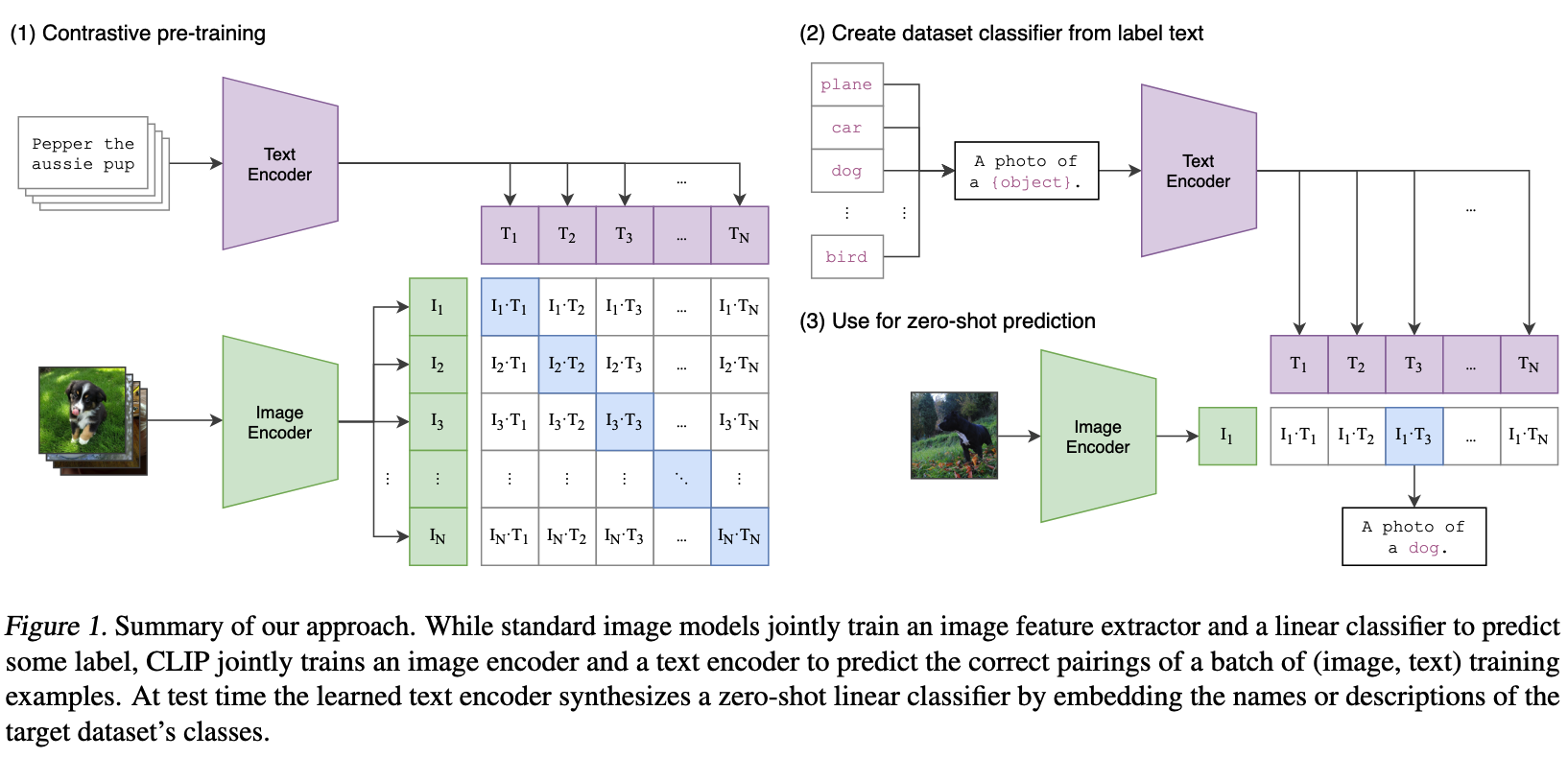
이 방식을 활용하기 위해서 두 개의 인코더를 활용한다. 하나는 이미지를 입력으로 받아서 이미지의 embedding을 만드는 인코더이고, 다른 하나는 택스트를 입력으로 받아서 택스트의 embedding을 만드는 인코더이다.
이미지 인코더는 기존에 Computer Vision에서 많이 사용되었던 ResNet이나 ViT를 활용하였다. Text Encoder는 기존의 Transformer를 활용하였다.
대조 학습
이렇게 추출된 이미지와 택스트의 embedding을 활용하여 대조 학습을 통하여 훈련을 한다. 대조학습의 방법은 간단하다. $N$개의 이미지와 택스트의 쌍이 존재한다고 하면, 이미지와 택스트의 쌍인 $(I_i, T_i)$를 유사하게 만든다. 그와 반대로 다른 이미지와 택스트의 쌍인 $(I_i, T_j) , i \neq j$는 유사하지 않게 만든다.
- 이미지와 택스트에서 Embedding, $I_i$와 $T_i$를 추출한다.
- 이 안에는 $N$개의 같은 쌍 데이터와 $N^2 - N$개의 다른 쌍 데이터가 존재한다.
- $N^2$개의 쌍에 대하여 코사인 유사도를 계산한다.
- $(I_i, T_i)$는 유사하게 만들고, $(I_i, T_j) , i \neq j$는 유사하지 않게 만든다. 즉, 대각선 행렬에 대하여 1이 되고, 나머지는 0이 되도록 만든다.
이 과정을 수없이 반복하게 되면, 이미지와 택스트는 멀티모달 공간안에서 유사한 공간에 위치하게 된다. 즉, 강아지라는 택스트와 실제의 강아지의 이미지가 유사한 백터공간안에 위치하게 된다는 것이다.
제로샷 추론
CLIP은 이렇게 훈련된 네트워크를 통해서 Zero-shot 방식으로 이미지 분류를 수행할 수 있다. 예를 들어, 어떤 이미지가 ‘개’, ‘고양이’, ‘자동차’ 중 무엇인지 분류하는 새로운 작업을 수행한다고 가정해 봅시다. 이러한 작업을 수행하기 위해서는 다음과 같은 과정을 거친다.
- 프롬프트 엔지니어링: 분류할 레이블들을 문장으로 만든다. (e.g., “a photo of a dog”, “a photo of a cat”, “a photo of a car”)
- 인코딩:
- 분류하려는 이미지 한 장을 이미지 인코더에 통과시켜 이미지 벡터를 얻습니다.
- 준비된 모든 텍스트 프롬프트를 텍스트 인코더에 통과시켜 여러 개의 텍스트 벡터를 얻습니다.
- 유사도 계산 및 예측:
- 이미지 벡터와 모든 텍스트 벡터 간의 코사인 유사도를 각각 계산합니다.
- 가장 높은 유사도 점수를 보인 텍스트 프롬프트를 최종 예측 결과로 선택합니다.
이 방식은 해당 분류 작업에 대한 어떠한 예제 이미지도 보지 않고(Zero-Shot), 오직 자연어 설명과의 유사도 비교만으로 문제를 해결한다. 이는 모델이 단순히 패턴을 암기한 것이 아니라, 시각적 개념을 언어적으로 ‘이해’하고 있음을 보여준다.
실험 결과 및 의의
-
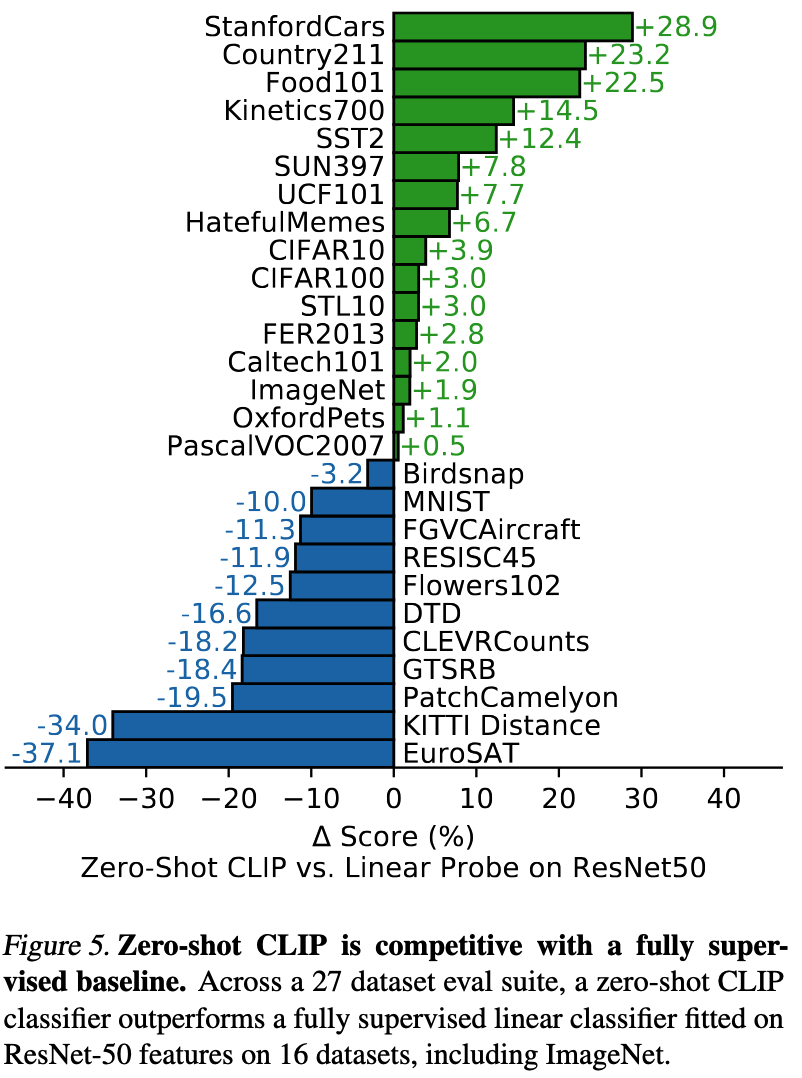
강력한 제로샷 성능: CLIP은 다양한 데이터셋에서 제로샷 성능만으로, 동일한 데이터셋에 완벽히 지도 학습된 ResNet-50 모델과 높은 성능을 보여주기도 하였습니다.
-
뛰어난 일반화 및 견고성: 스케치, 만화, OCR 등 기존 모델이 취약했던 ‘비정형적’ 이미지에 대해서도 훨씬 강건한(robust) 성능을 보였습니다.
-
멀티모달 AI의 기반 모델: CLIP이 만들어낸 고품질의 멀티모달 임베딩 공간은 이후 DALL-E 2, Stable Diffusion 같은 Text-to-Image 모델이나 LLaVA 같은 대화형 VLM의 핵심 구성 요소로 활용되며, 관련 생태계를 폭발적으로 성장시키는 기폭제가 되었습니다.
한계 및 결론
물론 CLIP이 만능은 아닙니다. 논문에서도 다음과 같은 한계를 명시합니다.
-
세밀한 분류의 어려움: 자동차 모델명, 꽃 품종, 위성 이미지 등 매우 전문적이고 세밀한 분류 작업에서는 여전히 해당 분야에 특화된 지도학습 모델보다 성능이 낮습니다.
-
추상적 개념의 한계: 이미지 속 객체의 수를 세거나, 가장 가까운 객체를 찾는 등의 추상적인 작업에는 약한 모습을 보입니다.
-
데이터 편향: 인터넷의 편향된 데이터를 그대로 학습한다.
결론적으로 CLIP은 ‘자연어’라는 풍부하고 저렴한 자원을 활용하여 시각 모델을 효과적으로 사전 훈련할 수 있음을 증명한 기념비적인 연구입니다. 특정 작업에 얽매이지 않고 범용적인 시각적 이해 능력을 갖춘 모델을 만드는 새로운 길을 열었으며, 현대 멀티모달 AI의 시작을 알린 논문으로 평가받고 있습니다.