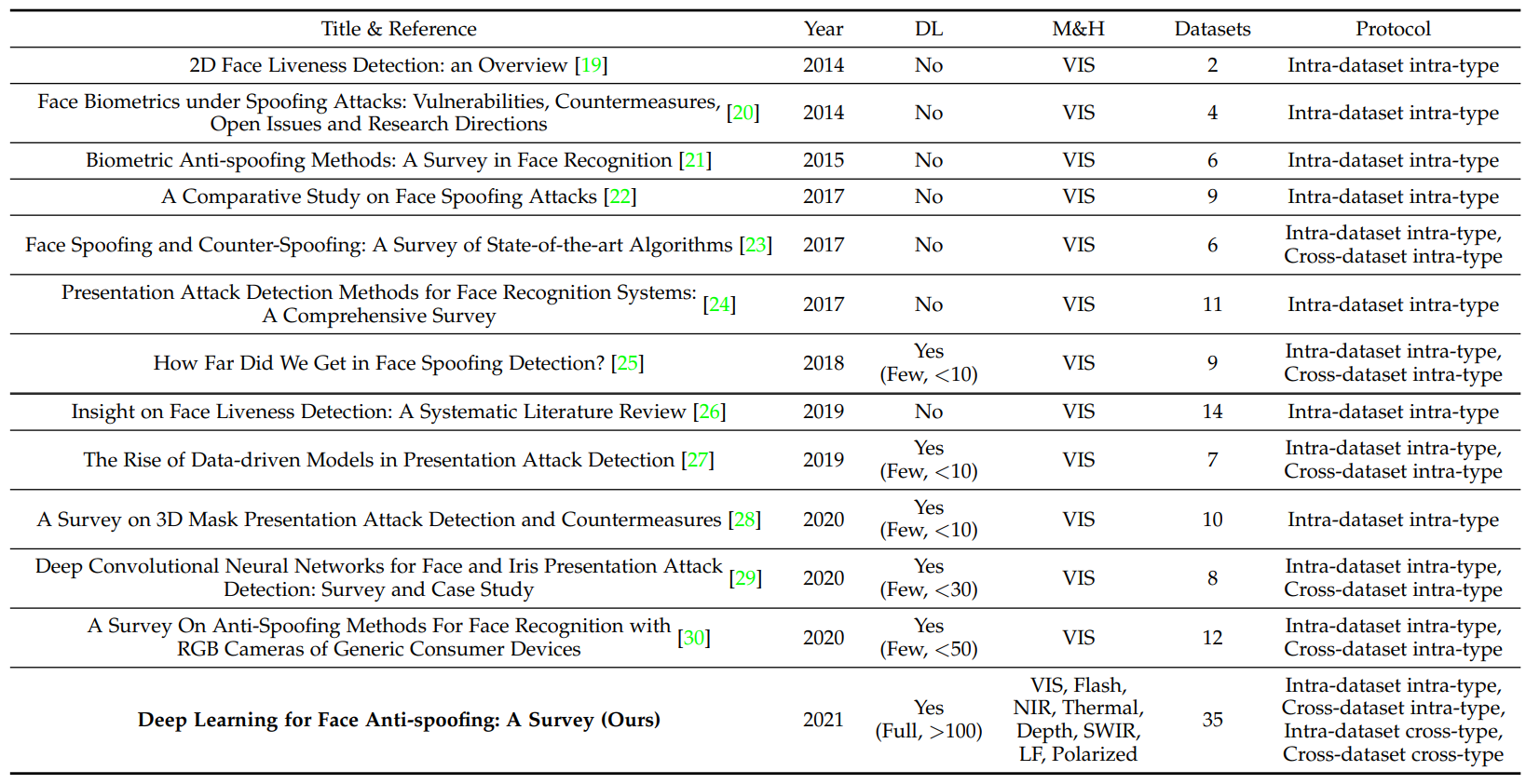
Deep Learning for Face Anti-Spoofing: A Survey
Introduction
Face recognition systems are vulnerable to presentation attacks (PAs) ranging from print, replay, makeup, 3D-masks. For secure face recognition system, researchers are actively searching to prevent the PAs.
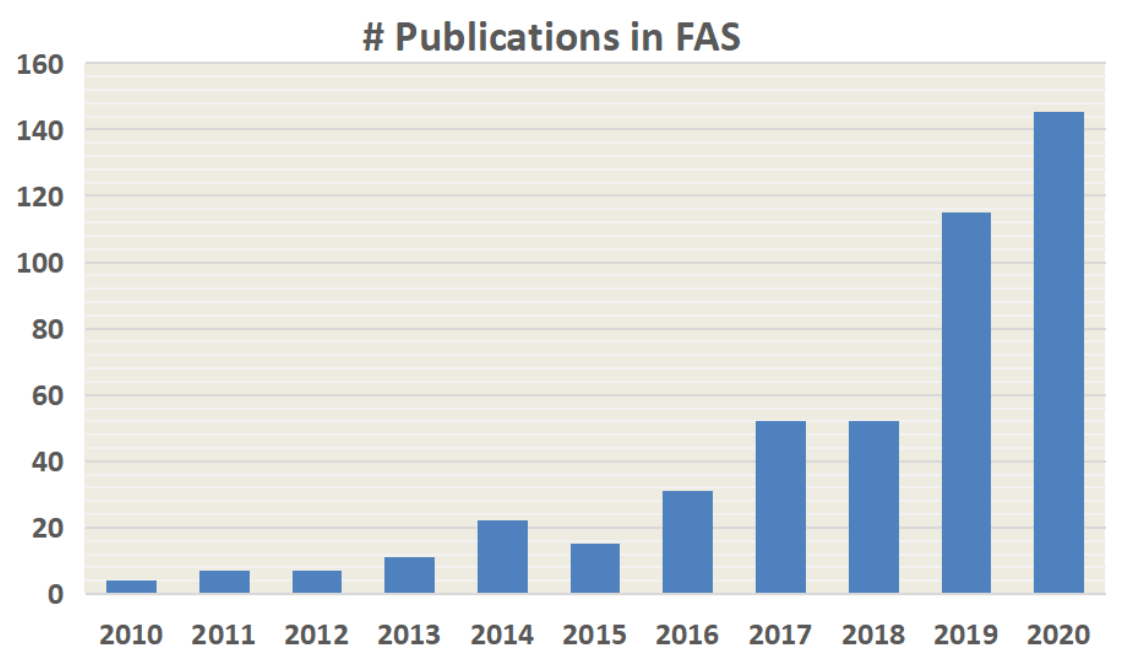
As shown in the graph, the number of publications have been increased in recent years.
In early stages of FAS, handcrafted feature based methods have proposed for presentation attacks detections(PAD). Most traditional algorithms are based on detecting human liveness cues and handcrafted features. These methods includes eye-blinking, face and head-movements(e.g. nodding and smiling), gaze tacking, and remote physiological signals(e.g. rPPG). These are captured from videos which is inconvenient for practical deployment. Moreover, these liveness cues are easily mimicked by video attacks.
Classical handcrafted descriptors (LBP, SIFT, SURF, HOG, and DoG) are designed for extracting effective spoofing patterns form various color spaces (RGB, HSV, and YCbCr).
Few hybrid (handcrafted + Deep Learning) and end-to-end deep learning based methods are proposed for both static and dynamic face PAD. Most works treet FAS as a binary classification problem. However CNN with binary loss might discover some arbitrary cues (e.g. screen bezel) but not the faithful spooning pattern.
Pixel-wise supervision provides more fine-grain context-aware supervision signals. Pseudo depth labels, reflection map, binary mask label, and 3D point cloud maps, are typical pixel-wise auxiliary supervisions.
A few generative deep FAS methods model the intrinsic spoofing patterns via relaxed pixel-wise reconstruction constaints. These models have limited numbers of deep learning methods.
Background
Face Spoofing Attacks
Attacks on automatic face recognition (AFR) system usuallay divide into two categories: digital manipulation and physical presentation attacks. Digital manipulations uses digital virtual domain. Physical presenatation attack present face upon physical mediums in front of physical face presentation attacks.
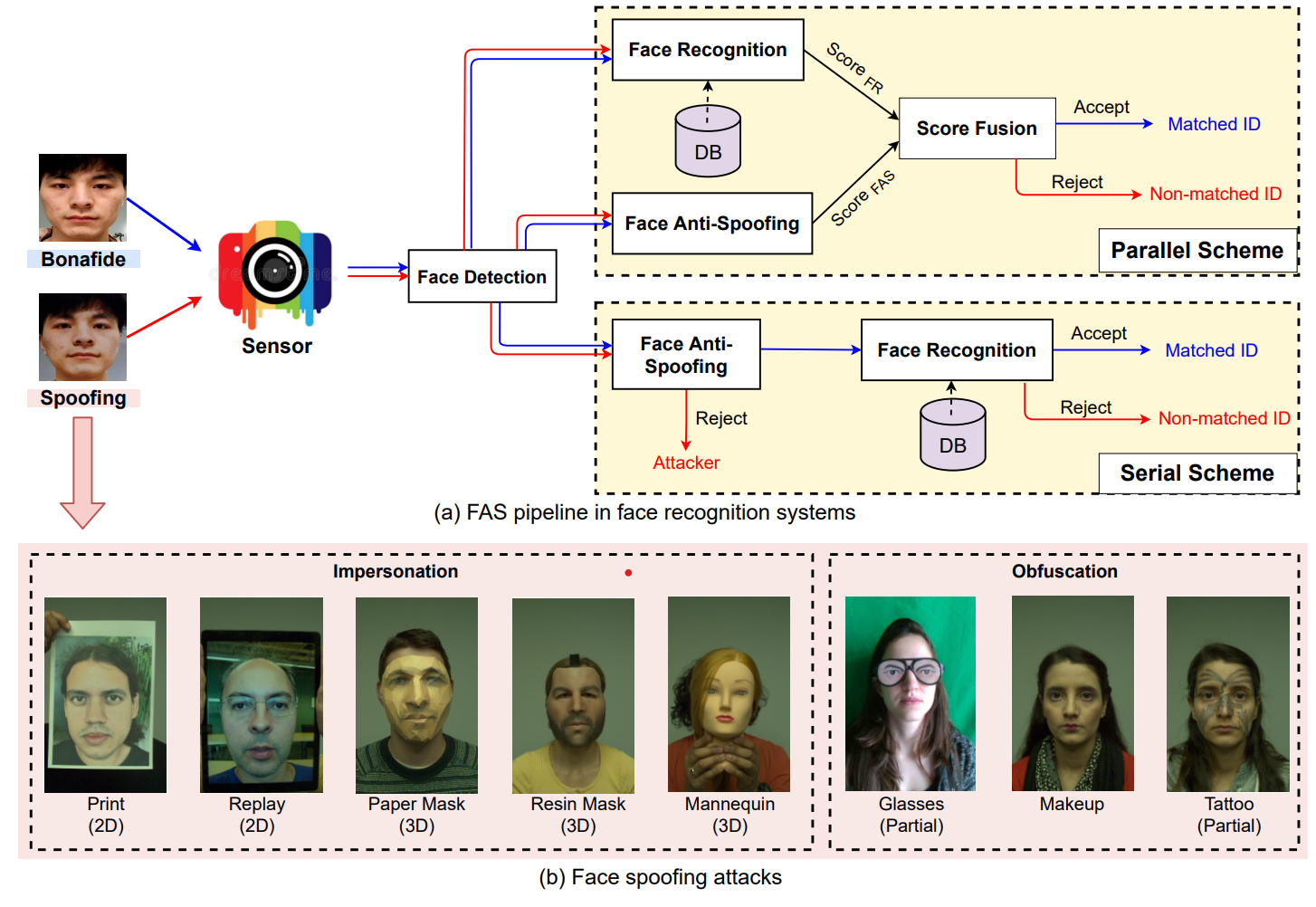
As Shown in the images, there are two ways to integrate FAS with AFR:
- Parallel fusion with predicted scores from FAS and AFR. The combined new final score is used to determine if the sample comes from a genuine user or not
- Serial scheme for early face PAs detection and spoofing rejection, thus avoiding face accessing the subsequent face recognition phase.
The image (b) represent some spoofing attack types. According to attacker’s intention, face PAs can be divided into two typical cases
- Impersonation : spoof to be recognized as someone else via copying genuine user’s factial attributes to special mediums such as photo, electronic screen, and 3D mask
- Obfuscation : hide or remove the attacker’s own identity using various methods such as glasses, makeup, wig, and disguised face
Based on the Geometric property, PAs are broadly classified into 2D and 3D attacks.
- 2D PAs are carried out by presenting facial attributes using photo or video to the sensors
- Flat/Wrapped printed photos
- Eye/mouth-cut photos,
- Digital replay of videos
- 3D PAs have become a new type of PAs as 3D printing technology. Face Masks are more realistic in terms of color, texture, and geometry. These masks are made of different materials
- Hard/Rigid mask : paper, resin, plaster, plastic
- flexible soft mask : silicon, latex
Based on the facial region covering, PAs be also separated as whole or partial attacks.
- Whole attacks are common
- Print photo
- Video replay
- 3D mask
- partial attacks are uncommon
- Part-cut print photo
- Eyeclasses
- Partial tattoo
Dataset for Face Anti-Spoofing
Large-scale and diverse dataset are pivotal for deep learning based methods during both training and evaluating phase.

As shown in the images thereare different kinds of dataset, It might contain just RGB images with similar setting or might have multiple modalities.
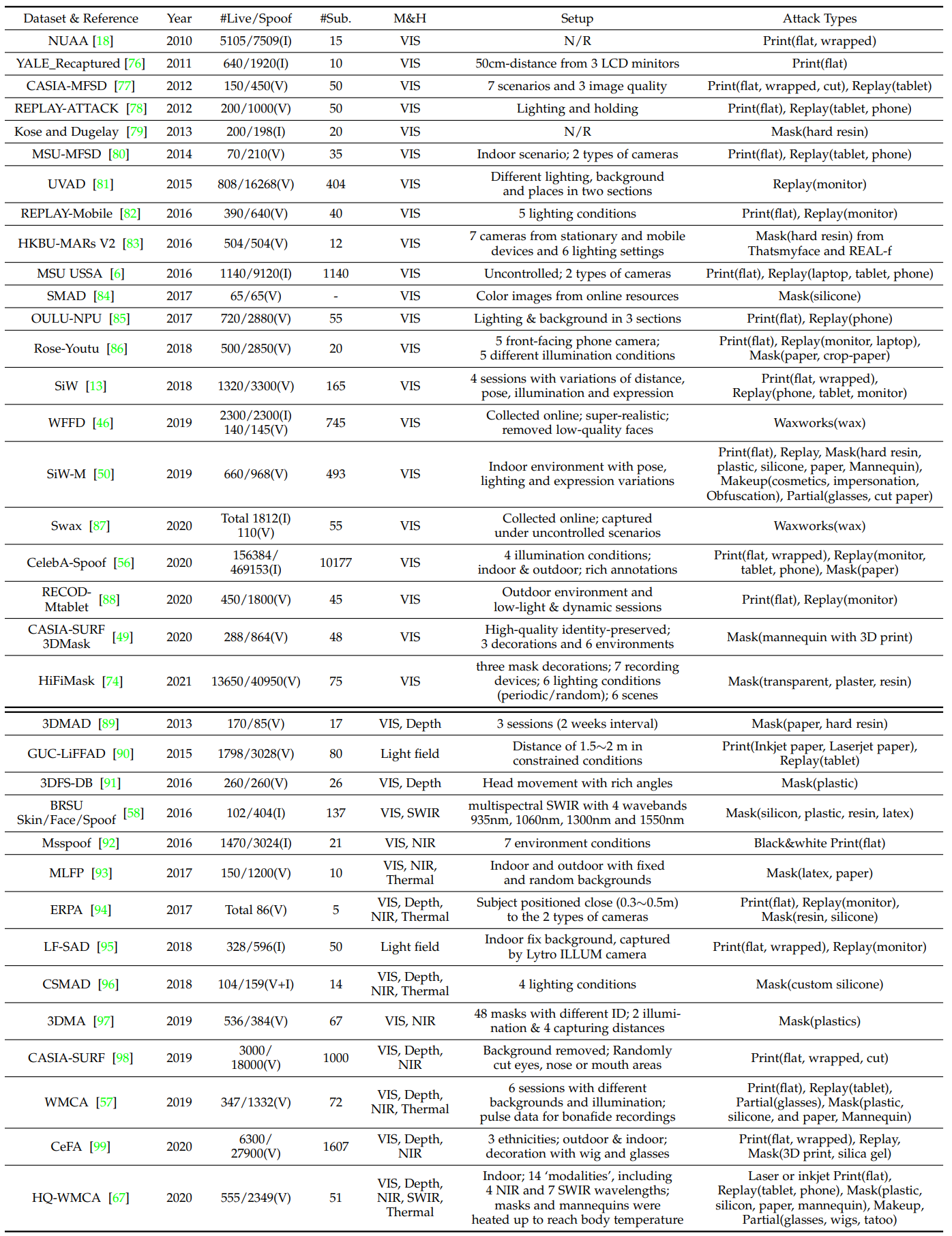
I and V in the “#Live/Spoof” denotes ‘images’ and ‘video’
There are three main trends for dataset progress:
- Large scale data amount
- CelebA-Spoof and HiFiMask dataset contains more than 600000 unages and 50000 videos, where most of them are PAs
- Diverse data distribution
- Besides common print and replay attacks (recorded in indoor), novel attack types are introduced.
- mutliple modalities and specialized sensors
- Apart from traditional RGB, recent dataset consider other sensors
- NIR
- Depth
- Thermal
- SWIR
- Other (Light field Camera)
- Apart from traditional RGB, recent dataset consider other sensors
Evaluation Metrics
FAS system focuse on the concept of bonafide and PA acceptance and rejection. Two basic metrics False Rejection Rate and False Acceptance Rate are widely used.
FAR is the ratio of incorrectly accepted spoffing attacks. FRR is the ratio of increectly rejected live accesses.
FAS follows ISO/IEC DIS 30107- 3:2017 standards to evaluate the performance of the FAS systems under different senarios.
The most commonly used metrics in intra- and cross-testing scenarios ais Half Total Error Rate(HTER), Equal Error Rate(EER), and Area Under the Curve (AUC).
HTER is found out by calculating the average of FRR and FAR. EER is a specific value of HTER at which FAR and FRR have equal values. AUC represents the degree of separablility between bonafide and spoofings.
Attack Presenataion Classification Error Rate(APCER), Bonafide Presentation Classification Error Rate (BPCER) and Average Classification Error Rate (ACER) suggested in ISO standard are also used for intra-dataset testing.
BPCER and APCER measure bonafide aand attack classification error rates, respectively. ACER is calulated as the mean of BPCER and APCER, evaluating the reliability of intra-dataset performance.
Evaluation Protocols
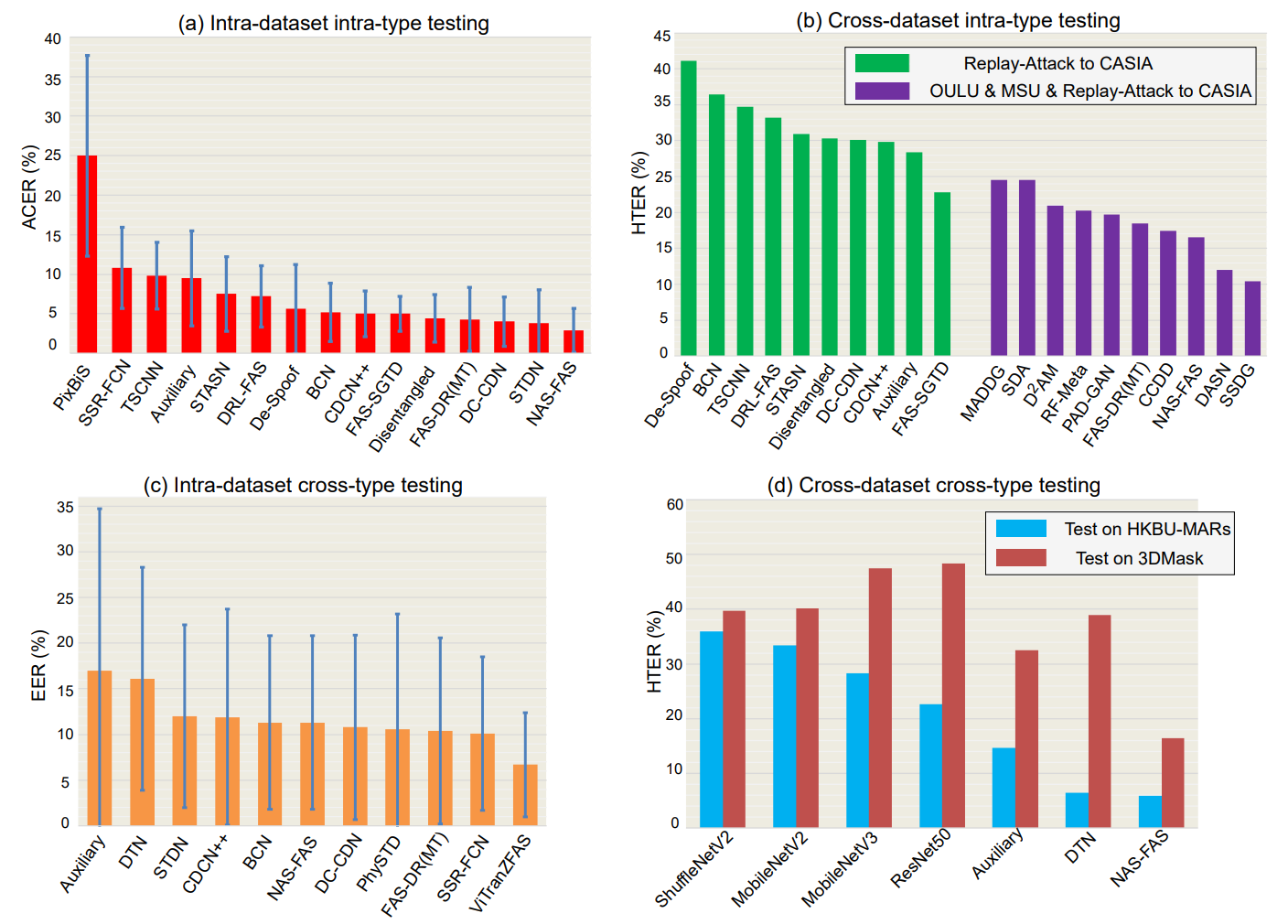
Intra-Dataset Intra-Type Protocol
Intra-dataset intra-type protocol has been widely used in most FAS datasets to evaluate the model’s discrimination abuility for spoofing detection under scenarios with slight domain shift.
As the training and testing data are from the same datasets, they share similar domain distribution in terms of the recording environment, subject behavior. Due to strong discriminative feature representation ability via deep learning, many methods have reached satisfied performance (<5% ACER) under small domain shifts about external encironments, attack mediums and recording camera variation.
Cross-Dataset Intra-Type Protocol
Cross-dataset level domain generalization ability measurement. This protocol tests on one or several datasets and then tests on unseen datasets.
Intra-Dataset Cross-Type Protocol
The protocol adopts ‘leave one attack type out’ to validate the model’s generalization for unknown attack types. One kind of attack type only appears in the testing stage.
Cross-Dataset Cross-Type Protocol
Cross Dataset Cross Type Protocol to measure the FAS model’s generalization on both unseen domain and unknown attack types.
Deep FAS with Commercial RGB Camera
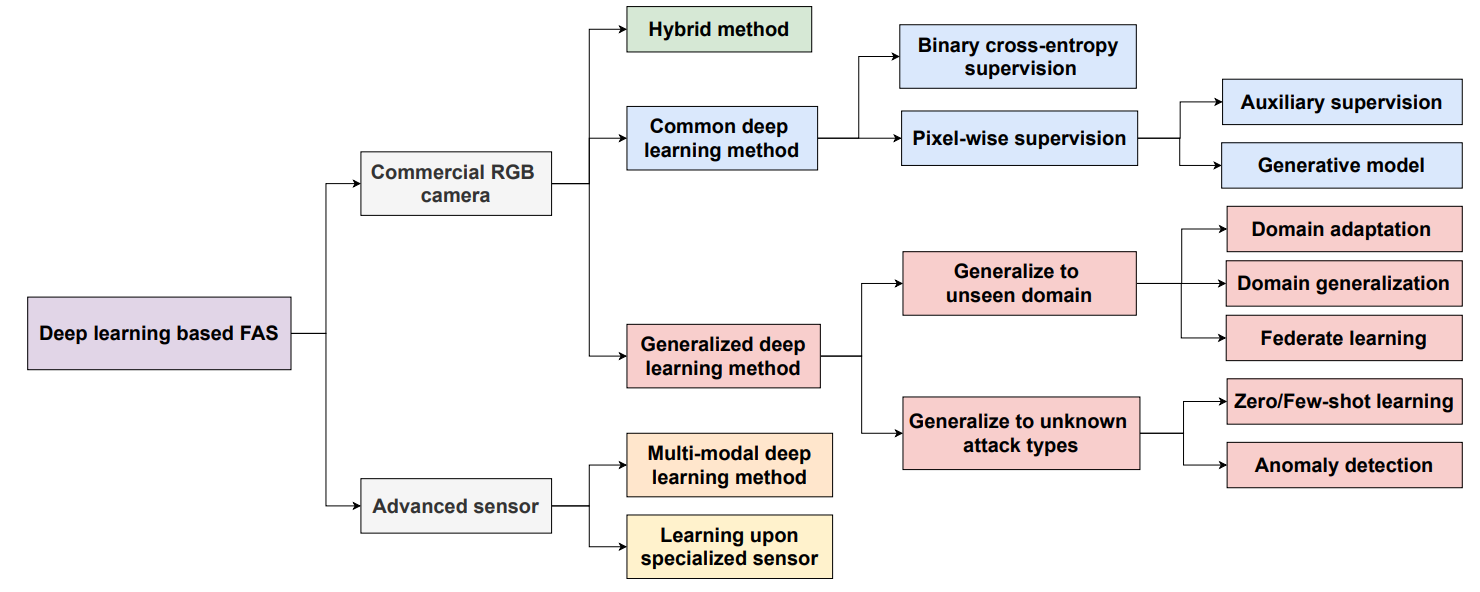
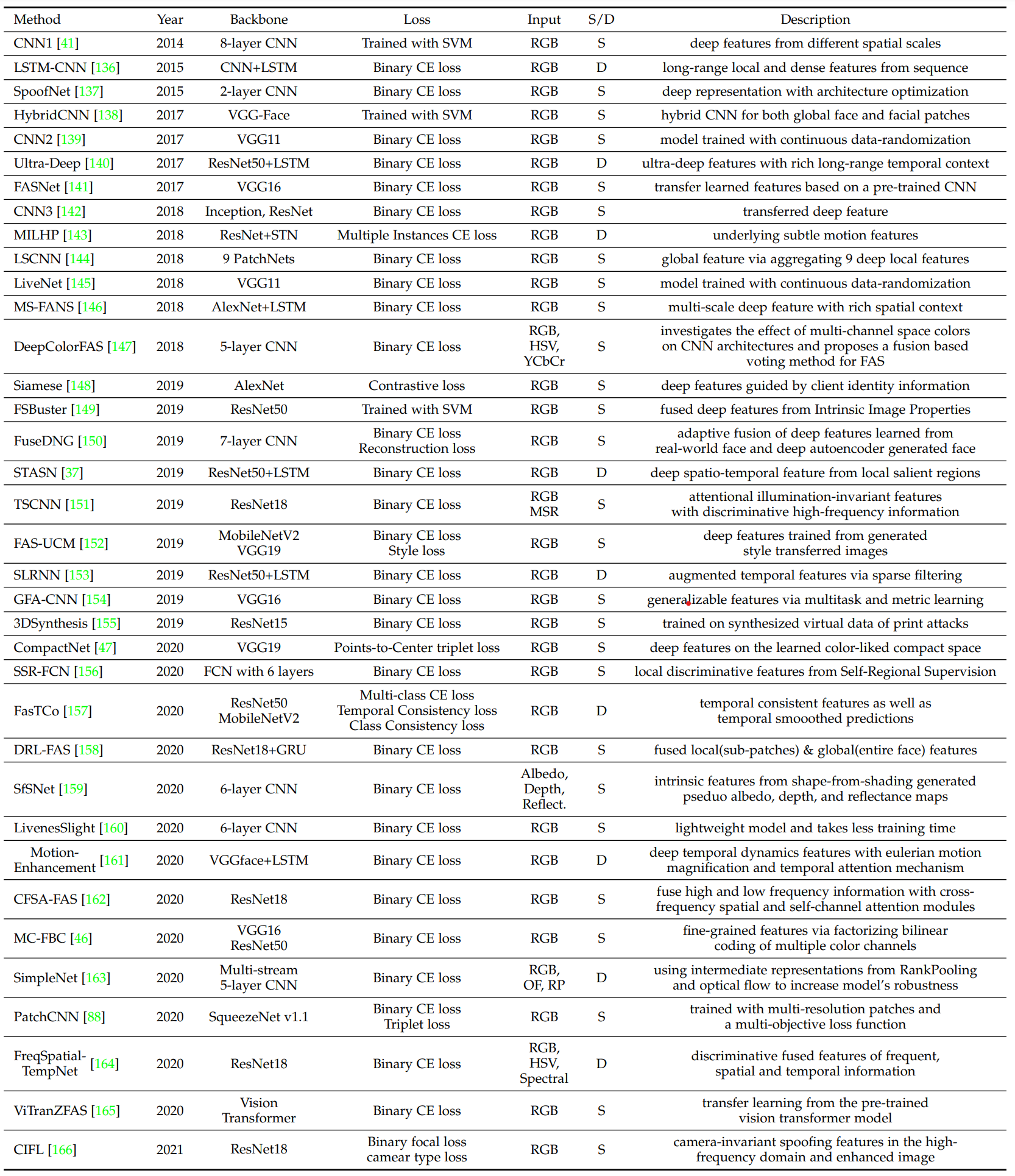
Comercial RGB camera is widely used in many real-world application scenarios. There are three main categories for exisiting deep learning based FAS methods using comercial RGB camera: Hybrid type learning methods combining both handcrafted and deep learning features; common end-to-end supervised deep learning methods; generalized deep learning methods.
Hybrid Method
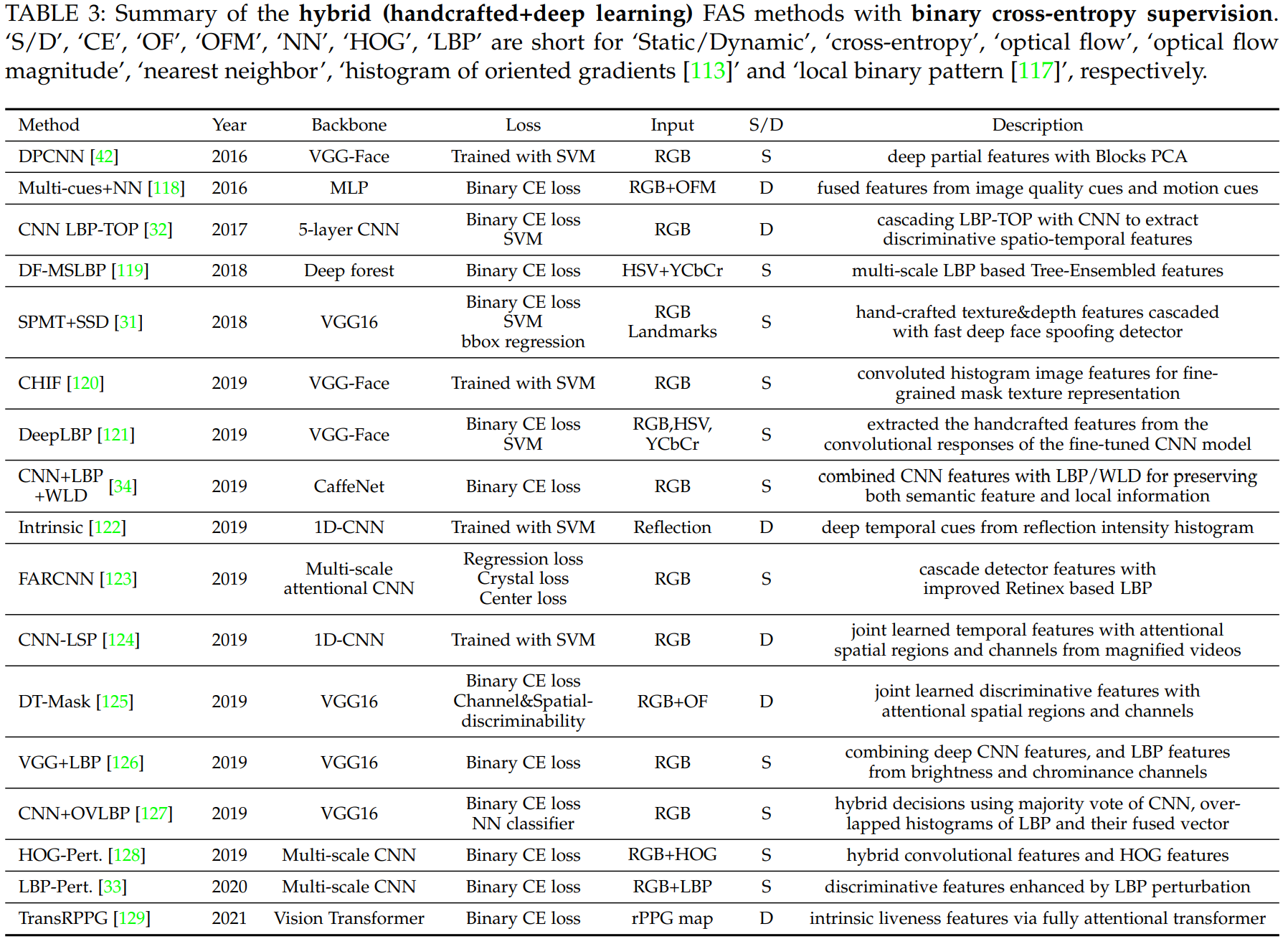
DL and CNN achieved great success in many computer vision tasks. However for FAS, they suffer the overfitting problem due to the limited amount and diversity of the training data. Handcrafted features have been proven to be discriminative to distinguish bonafide from PAs. Some recent works combine handcrafted features with deep features for FAS. These Hybrid methods can be separated into three main categories.
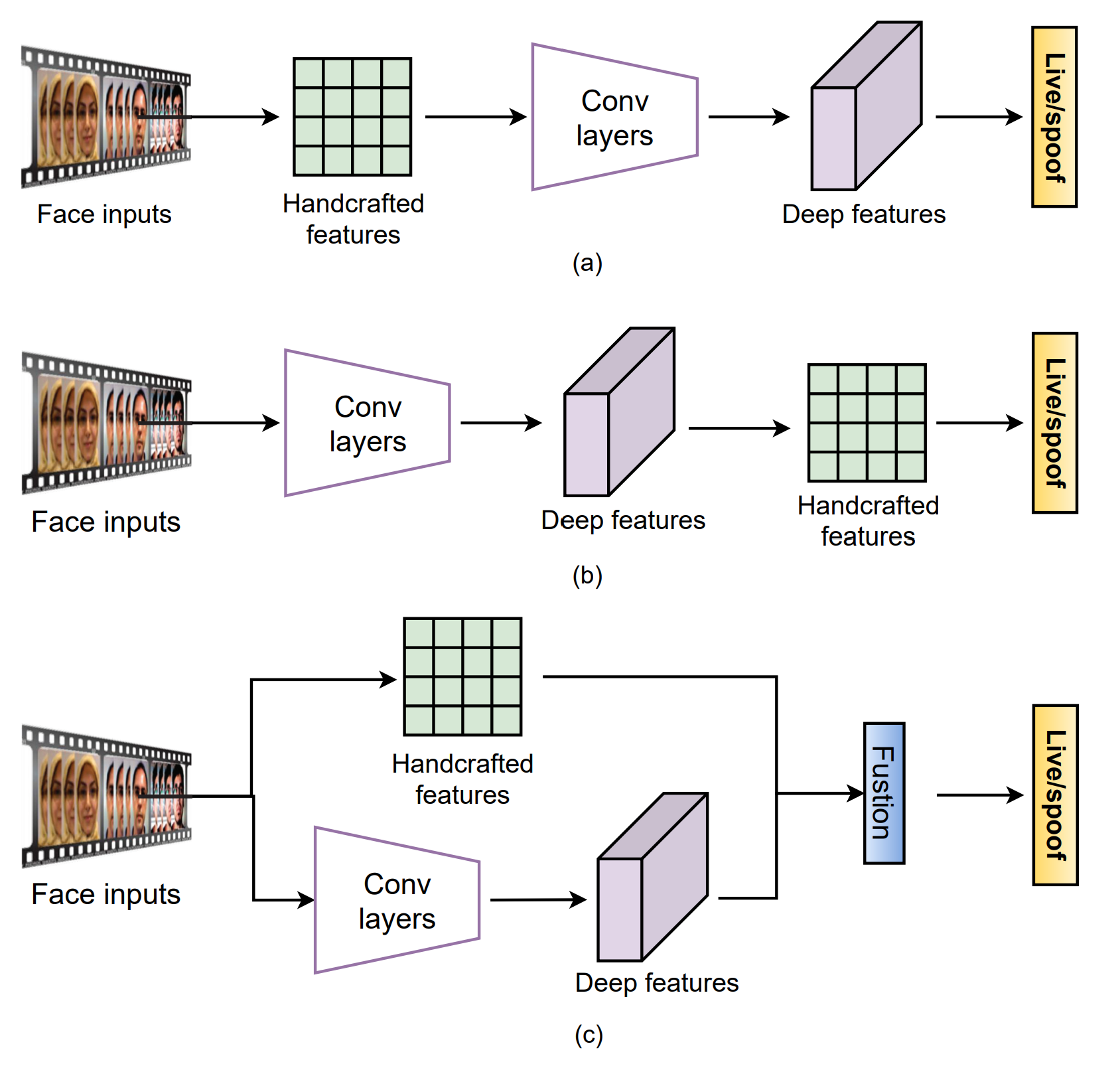
The first method is to extract handcrafted features from inputs then employ CNN for semantic feature representation.
The Second method is to extract handcrafted features from deep confolutional features.
The thrid method is to fuse handcrafted and deep convolutional features fro more generic representation.
Common Deep Learning Method
Common deep learning based methods directly learn the mapping functions from face inputs to spoof detection. Common deep learning frameworks usually include
- direct supervision with binary cross-entropy loss
- pixel-wise supervision with auxiliary task
- generative models.
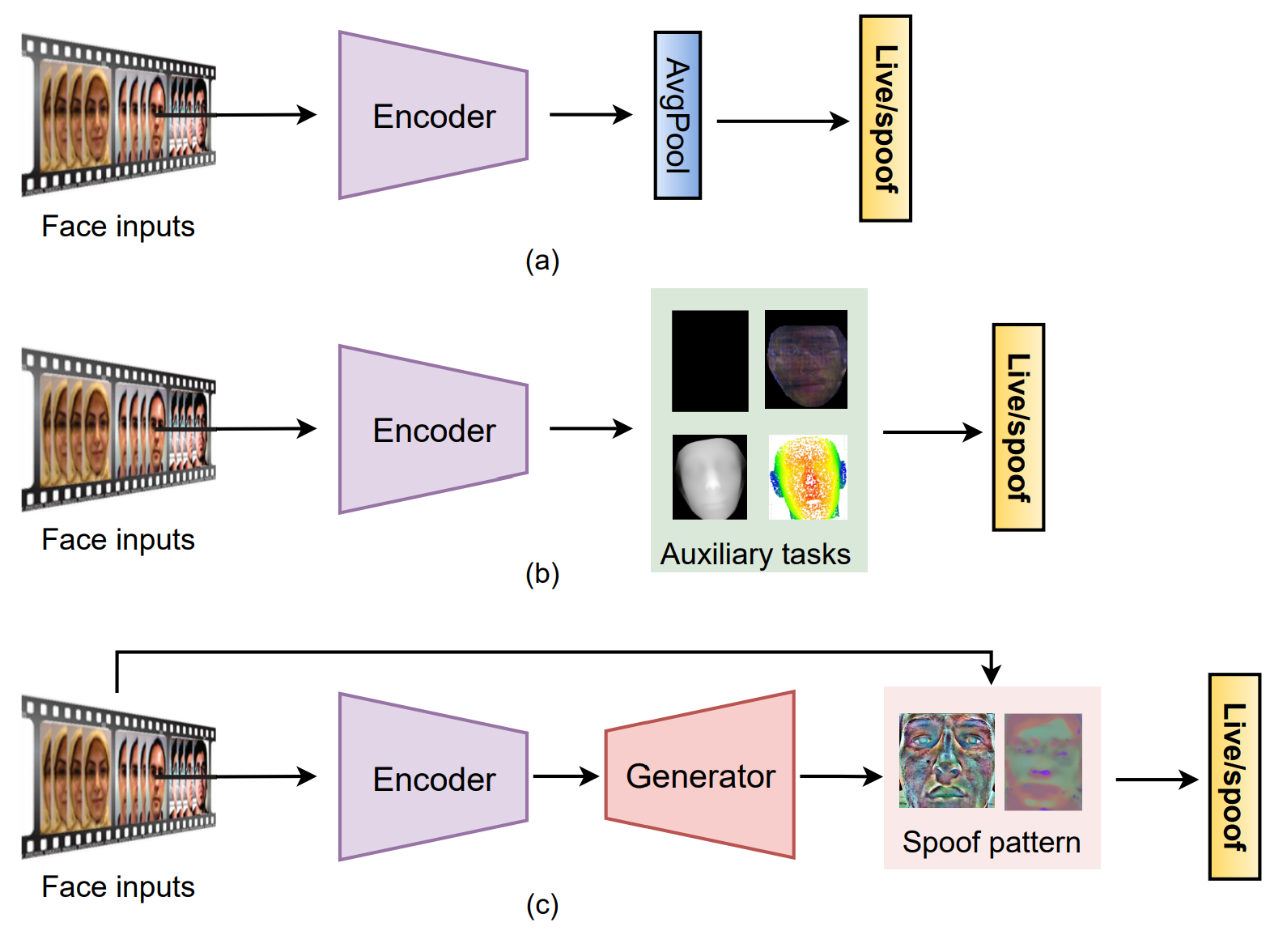
Direct Supervision with Binary Cross-Entropy loss
FAS can be intuitively treated as a binary classification task. Numerous end-to-end deep learning methods are directly supervised with binary cross-entropy(CE) loss as well as other extented losses.
Researchers have proposed various network architecture supervised by binary CE. There are few works modifying binary CE loss to provide more discriminative supervision signals
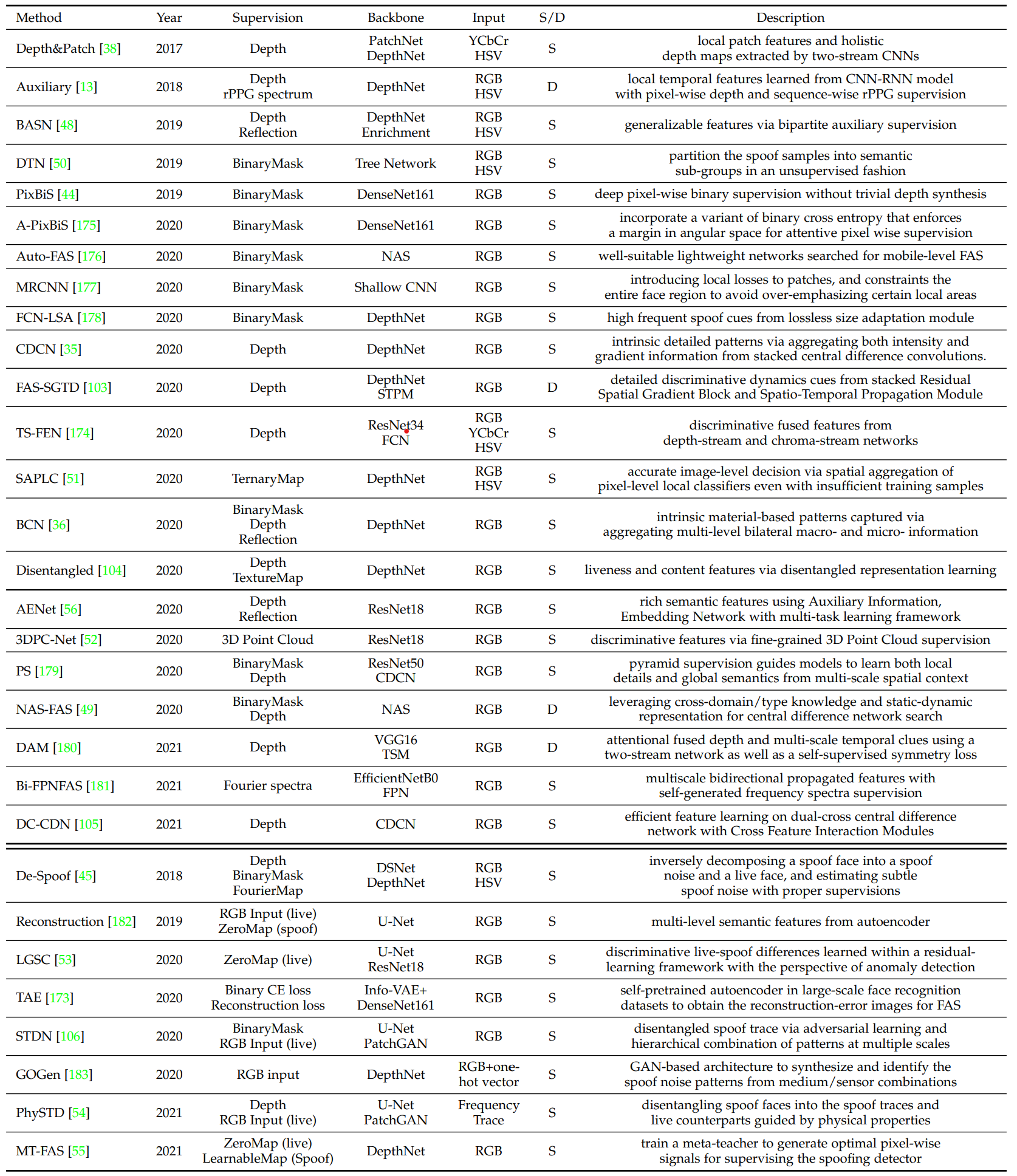
Pixel-wise Supervision
Pixel-wise supervision can provide more fine-graned and contextual task-related clues for better intrinsic feature learning. There are two type of pixel-wise supervision. One based on the physical clues and discriminative design philosophy, auxiliary supervision signals. The other generative models with explicit pixel-wise supervision are recently utilized for generic spoofing parttern estimation.
Pixel-wise supervision with Auxiliary Task
According to human knowledge, most PAs(e.g. plain printed paper and electronic screen) merely have no genuine facial depth information. As a result, recent works adopt pixel-wise pseudo depth labels to guide the deep models, enforcing them predict the genuine depth for live samples, while zero maps for the spoof ones. Another method is to use binary mask.
Pixel-wise supervision with Generative Model
Mine the visual spoof patterns existing in the spoof samples, aming to provide a more intuitive interpretation of the sample spoofness.
Generalizing Deep Learning Method
Common end-to-end deep learning based FAS methods might generalize poorly on unseen dominant conditions and unknown attack types. Therefore these methodes are unreliable to be applied in practival applications with strong security needs. There are two methods on enhancing generalization capacity of the deep FAS models. One is domain adaptation and generalization techniques. The other is zero/few-shot learning and anomaly detection.
Generalization to Unseen Domain
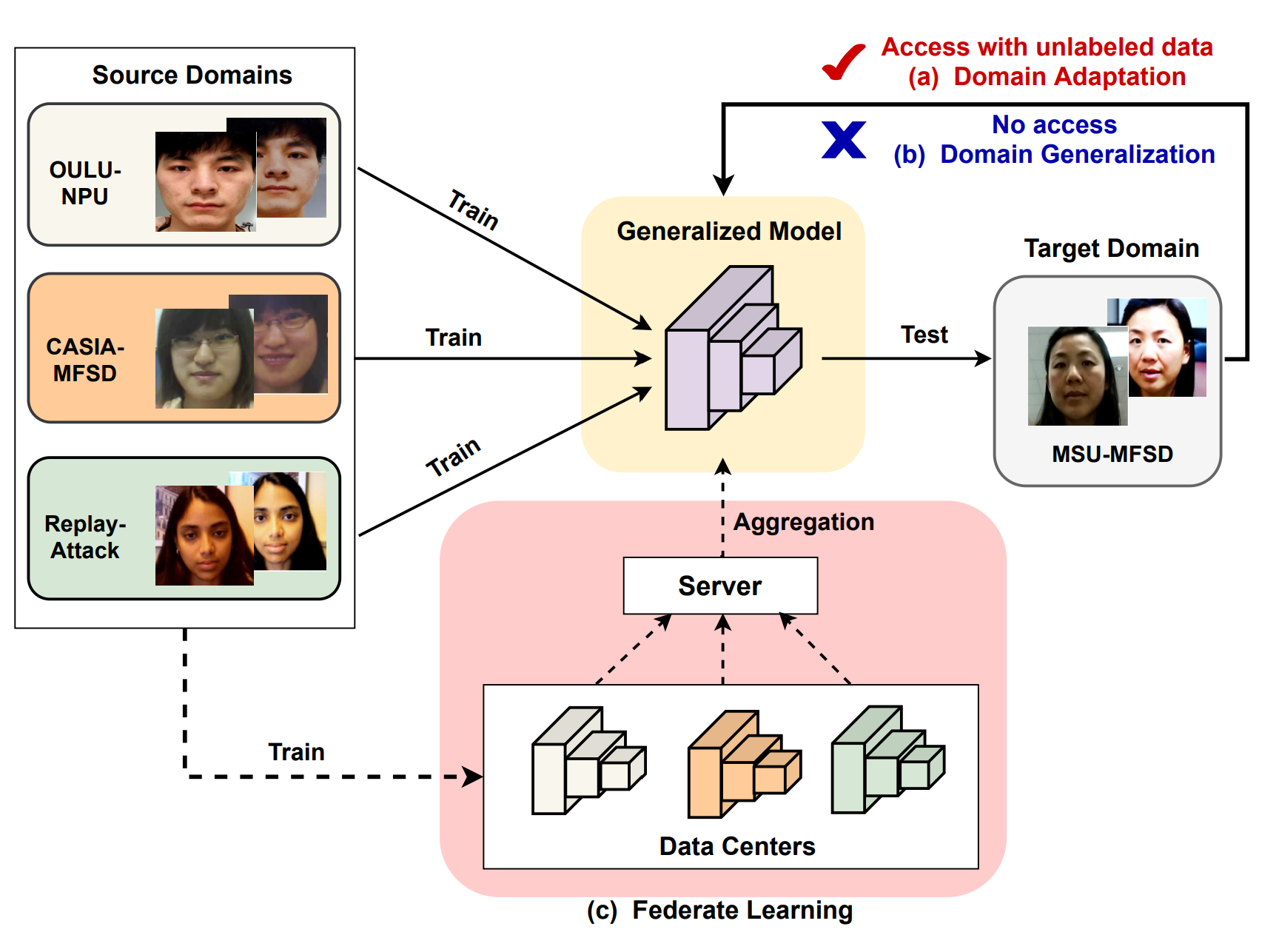
Domain adaptation technique leverage the knowledge from target domain to bridge the gap between source and target domains. Domain generalization helps learn the generalized feature representation from multiple source domain directly withous any access to target data. Federate learning framework is introduced in learning gneralized FAS models while preserving data privacy.
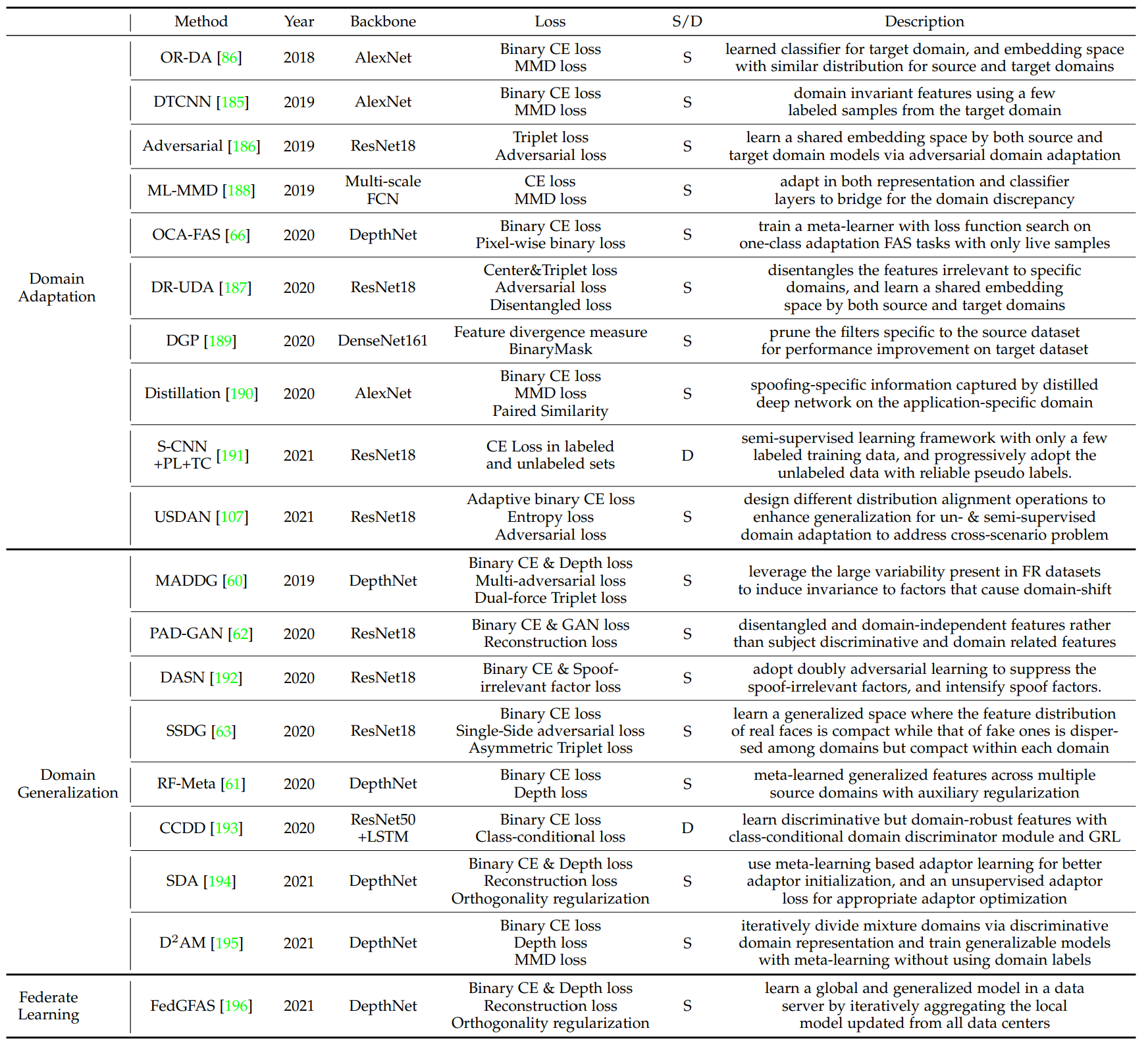
Domain Adaptation
Domain Adaptation technique alleviate the discrepancy between source and target domains. The distribution of source and target features are matched in a learned feature space. If the features have similar distrivutions, a classifier trained on features for the source samples can be used to classify the target live/spoof samples. However, it is difficult and expensive to collect a lot of unlabed data for traning.
Domain Generalization
Domain generalization assumes that there exists a generalized feature space underling the seen multiple source domains and the unseen but related target domain. Learned model from seen source domain can generalize well to the unseen target domain.
This is a new hot spot in recent years. Domain generalization benefits FAS models to perform well in unseen domain, but it is still unknown whether it deteriorates the discrimination capability for spoofing detection under the seen scenarios.
Federate Learning
A genearlized FAS model can be obtianed when trained with face images from different distribution and different types of PAs. Federate learning, a distributed and privacy-preserving machine learning techinques, is introduced in FAS to simulataneously take advantage of rich live/spoof information available at different data owners while maintaining data privacy.
To be specific, each trains its own FAS model. Server learns a global FAS model by iteratively aggregating model updates. Then the converged global fAS model would be utilized for inference.
This solve the privacy of data sets, but neglects the privacy issues in the model level.
Generalization to Unknown Attack Types
FAS models are vulnerable to emerging novel PAs. There are two general way of detecting unknown spoofing attack detection. One is zero/few-shot learning. The other is anomaly detection.
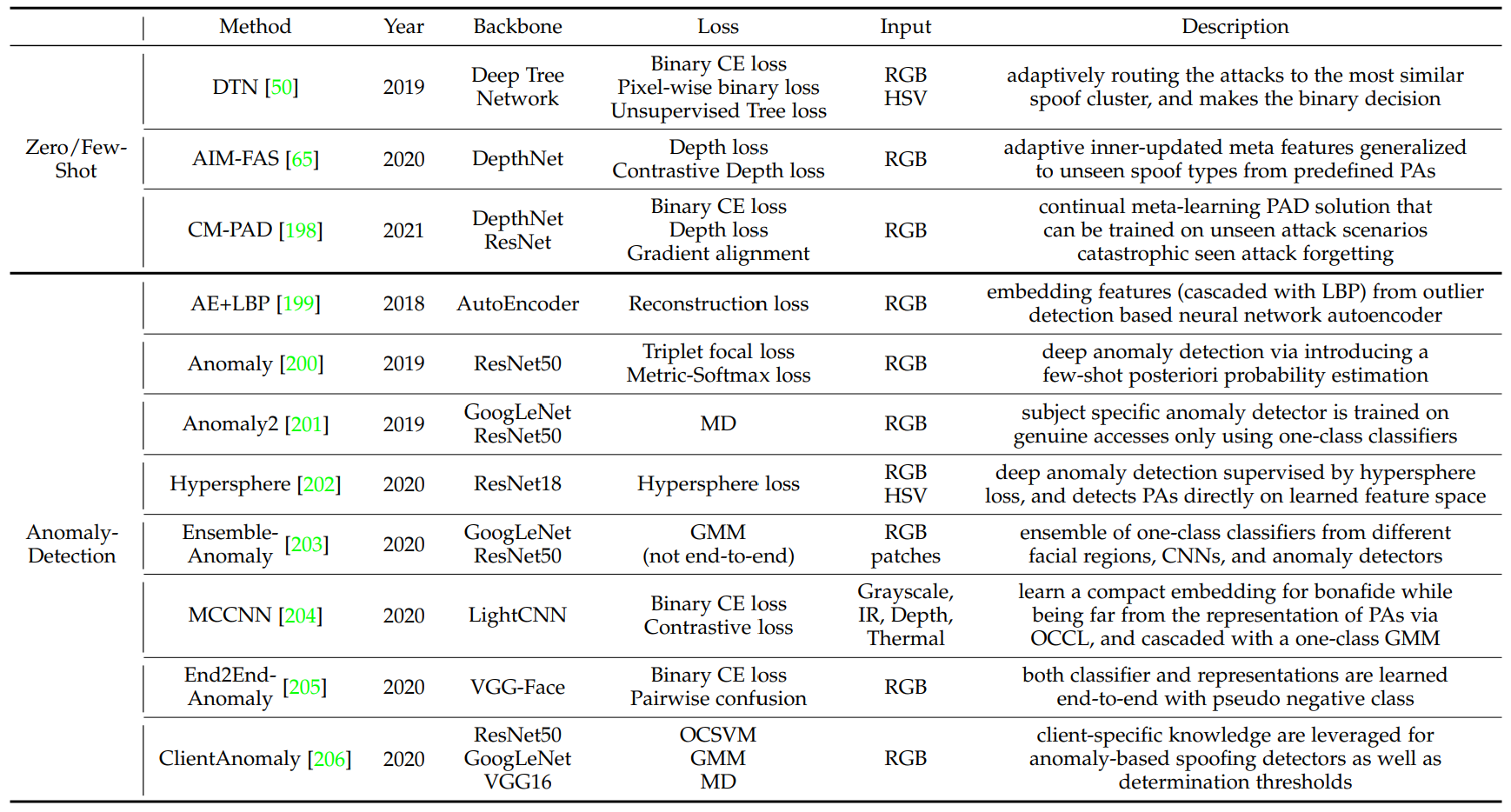
Zero/Few-Shot Learning
Zero-Shot Learning aims to learn generalized and discriminative features from the predefined PAs for unknown novel PA detection. Few-Shot learning aims to quickly adapt the FAS model to new attacks by learning from both the predefined PAs and the collected very few samples of the new attack.
The performance drops obviously when the data of the target attack types are unavailable for adaptation. The failed detection usually occurs in the challenging attack types, which share similar appearance distribution with the bonafide.
Anomaly Detection
Anomaly detection for FAS assumes that the live samples are in a normal class as they share more similar and compact feature representation while features from the spoof samples have large distribution discrepancies in the anomalous sample space due to the high variance of attack types and materials. Anomaly detection trains a reliable one-class classifier to cluster the live samples accurately. Then any samples outside the margin of the live sample cluster would be detected as the attack.
Anomaly detection based FAS methods would suffer from discrimination degradation.
Deep FAS with Advanced Sensor
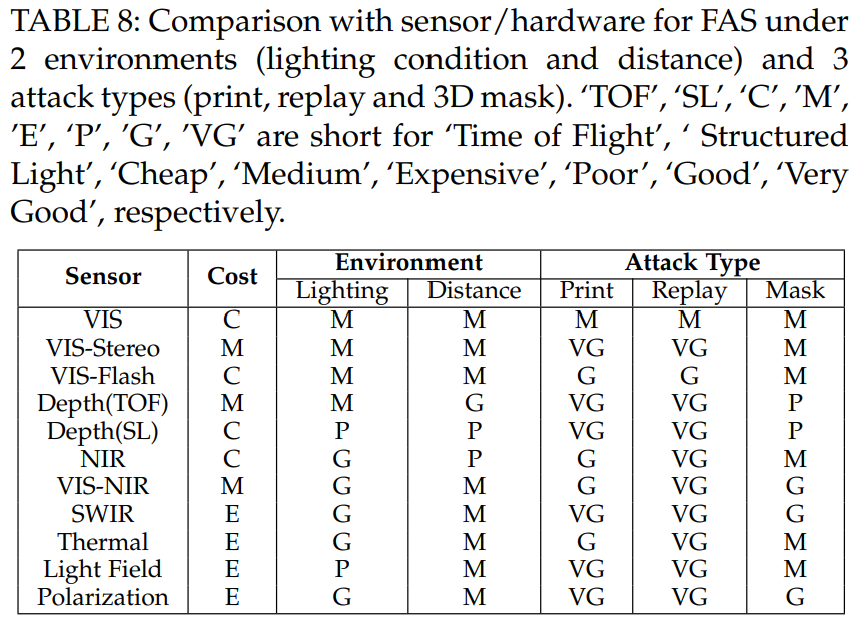
Uni-Modal Deep Learning upon Specialized Sensor.
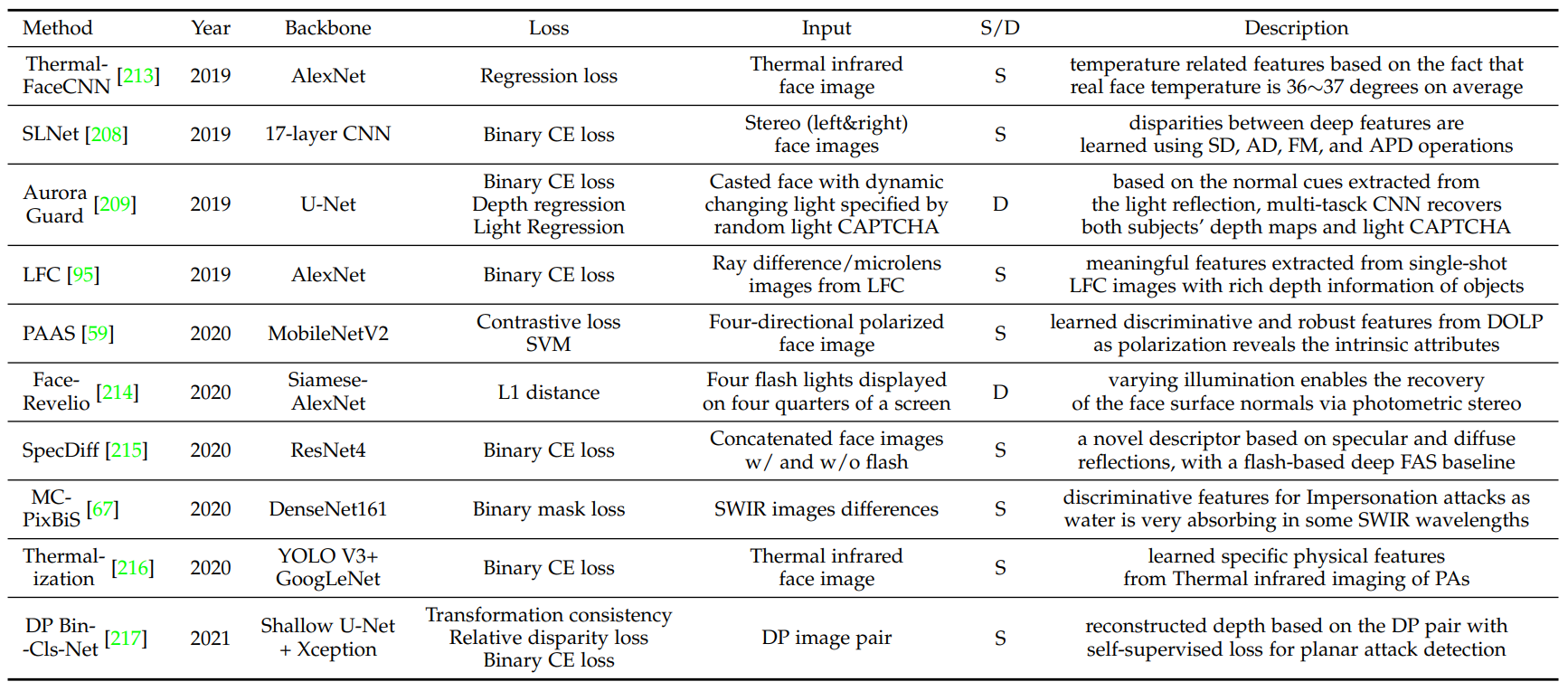
Multi-Modal Deep Learning
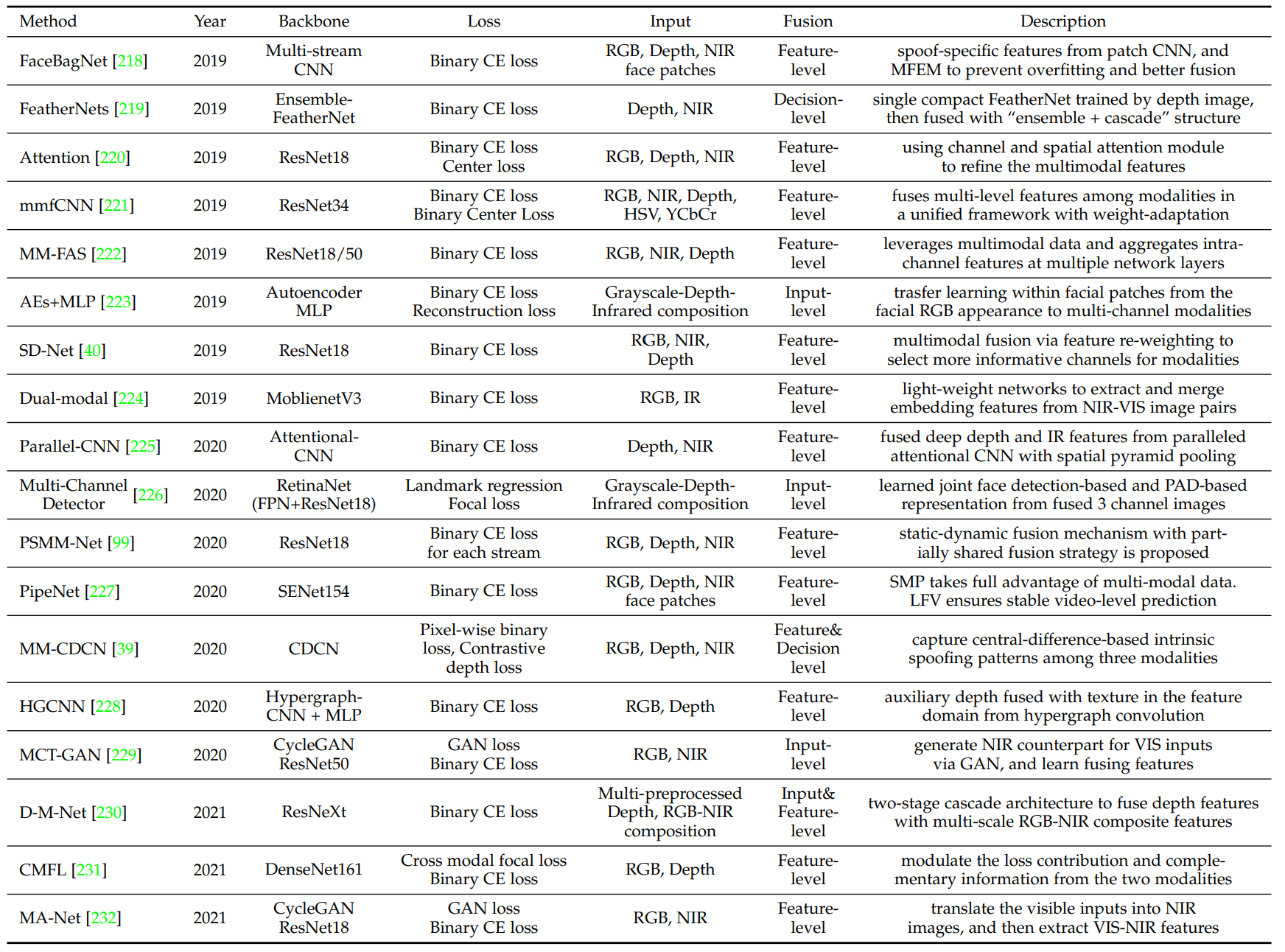
Multi-modal FAS with acceptable costs are increasedly used in real-world application.
Multi-Modal Fusion
Mainstream multi-modal FAS methods focus on feature level fusion strategy. There are few works that consider input-level and decision level fusions.
Cross-Modal Translation
The missing modality issues can be raised when using multi-modal FAS. Therefore some uses cross-modal translation techniques to generate missing modal data.