An Image is Worth 16x16 Words: Transformers for Iamge Recognition
Self-attention-based 구조는, 특히 Transformer 계열은, natural language processing을 사용때 가장 많이 사용하는 model입니다. 가장 많이 사용하는 방식은 large text corpus들 이용해 pretrain하고 비슷한 task-specific data를 이용해 fine-tune 하는 방식을 이용 합니다.
Computer vision에서는 convolution 구조가 가장 많이 사용 됩니다. CNN-like 구조에 self-attention을 추가하는 연구는 많이 이루어졌습니다. 하지만, 여전히 large-scale image recognition에서는 ResNet같은 구조가 state-of-art입니다.
Mid-sized datasets, ImageNet without strong regulariztion에서, ViT model은 정확도가 ResNet 보다 몇 퍼센트 떯어진다. 이는 Transformer가 가지고 있는 inductive bias가 CNN에 비해 적기 때문이다. 그래서 데이터의 양이 적을때, 일반화가 잘 되지 않습니다.
더 많은 데이터를 사용하고 적절한 pre-training과 task transfer를 할 경우, Vision Transformer는 좋은 결과 값을 가집니다. 이를 통해서, large-scale training은 inductive bias보다 우위에 있습니다.
Related Work.
Transformer는 많은 NLP task에 대하여 state of the art 방식입니다. 많은 Transformer 기반의 model은 large corpora를 사용하여 pre-train을 하고, 그 다음에 각각의 task에 맞춰 fine-tune을 하는 방식으로 이루어집니다.
이미지에 self-attetion을 사용하는 가장 기본적인 방식은 하나의 픽셀을 각각의 픽셀에 연결하는 방식입니다. 하지만 실재로 사용하기엔 입력값이 크기에 연산량도 기하급수적으로 증가합니다. 이러한 많은 specialized attention architecture 들은 좋은 결과를 가지고 있지만, hardware accelerator에 효율적으로 implement 하기에는 많은 어려움이 있습니다.
ViT model 과 가장 유사한 model은 Cordonnier et al(2020)입니다. 이 model은 입력 값에서 2x2 patch를 추출 합니다. 그 후에 self-attention을 사용합니다.
Convolutional Neural Network와 self-attention을 결합하거나, CNN을 통하여 얻은 결과값에 self-attention은 사용하는 방식에 많은 연구가 이루어지고 있습니다.
Image GPT(iGPT)는 이미지의 해상도와 색영역을 줄이고 난 다음에 Transformer를 적용했습니다. 이 model은 unsupervised한 방식으로 훈련했습니다. 결과물은 fine tuning을 하거나, linearly 탐색을 통해서 classification을 할 수 있습니다.
추가적인 데이터의 사용은 model을 state-of-the-art performace를 달성할수 있도록 합니다.
Method
ViT은 Transformer의 구조를 거의 변경없이 따르고있습니다.
Vison Transformer (ViT)
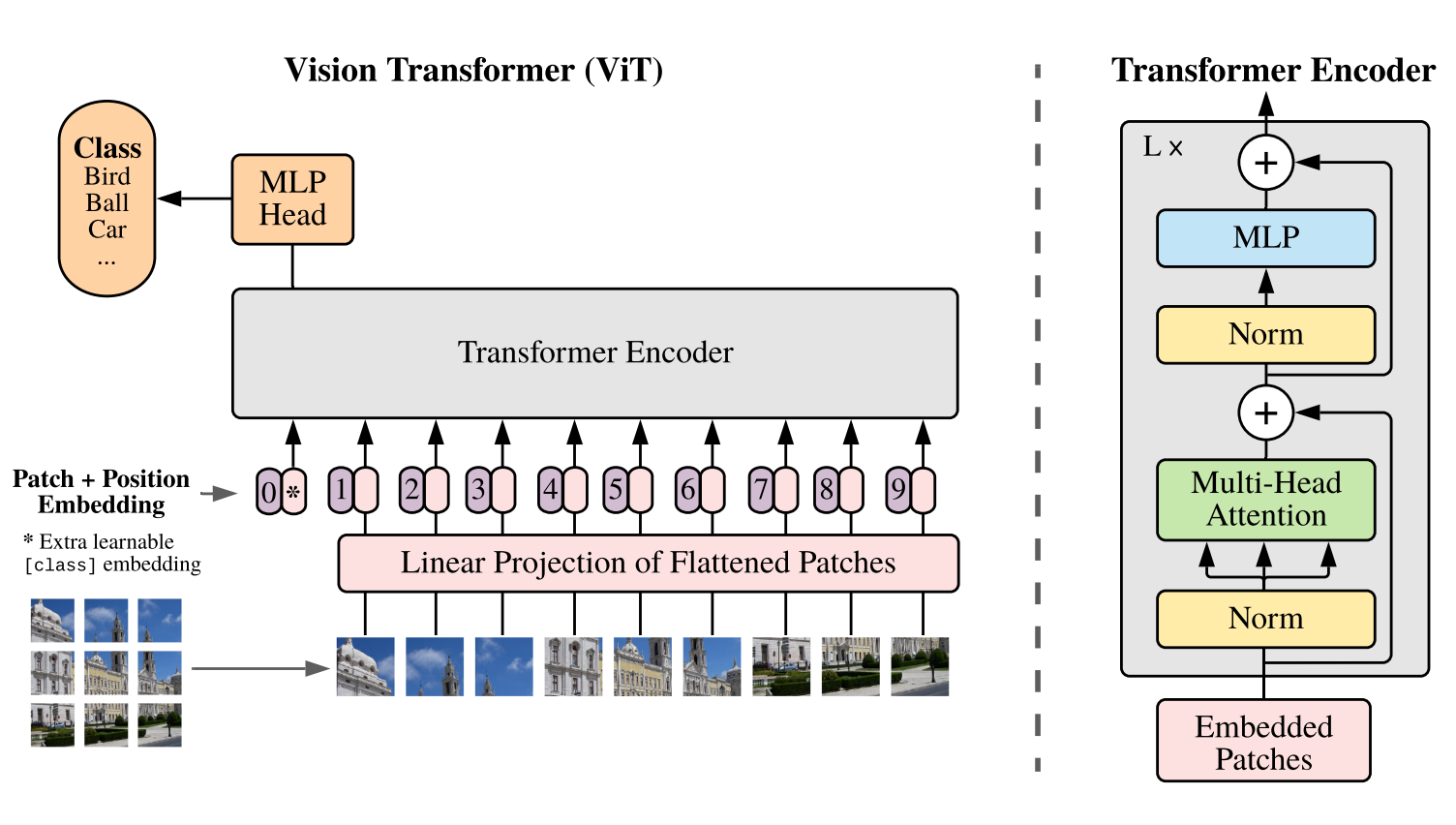
Transformer는 input을 1D sequence로 받습니다. 이미지를 처리하기 위해서, 이미지를 여러장의 patch sequence로 만들어여합니다.
Transformer가 고정된 D 차원의 백터를 모든 layer에 사용합니다. 비슷하게, 각 patch들은 flatten하고, trainable linaer projection을 사용해 D차원의 백터로 mapping 합니다.
Embeding patch의 sequence 가장 앞에 learnable embedding을 붙입니다. 이 patch는 image representation y의 역할을 합니다. Pretraining을 할때, fine tuning을 할때, classification head는 learnable embedding patch에 attach되어있습니다. Classification head는 pre0-training일때 MLP를 사용하고, fine-tuning 일때, single linear layer를 사용합니다.
Position embedding은 patch embedding이 끝나고 적용됩니다. 이는 각 patch의 positional information알 유지하기 위해서 입니다. Learnable 1D position embedding을 사용합니다. 결과값은 encoder의 입력값으로 사용됩니다.
Transformer의 encoder는 multihead self-attention과, MLP block이 alternate하는 형태로 이루어져 있습니다. Layernorm은 block 시작 전에, residual block은 block 끝난 후에 적용됩니다.
MLP는 두 layer로 GELU non-linearity를 사용합니다.
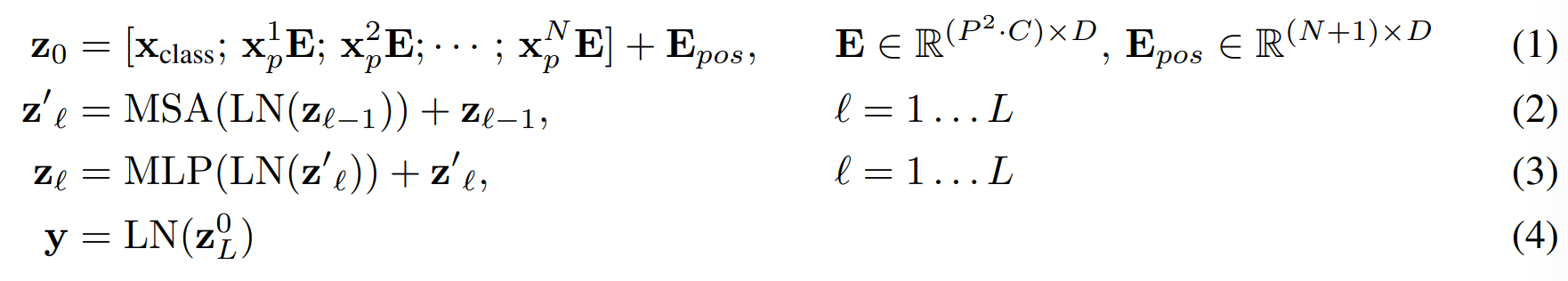
Inductive bias
Vision Transformer는 CNN보다 더 작은 image-specific inductive bias를 가지고 있습니다. ViT에서 Self-attention layer는 global하는 반면 MLP layer만 local하고, translationally equivariant 하다.
Two-dimensional neighborhood structure는 거의 사용되지 않습니다. 가장 처음에 image를 patch로 자를때 와 fine-tuning 할때 positional embedding을 다른 해상도로 adjust 할때 사용됩니다. 가장 처음에 positional embedding은 2d position에 관한 아무런 정보를 가지고 있지 않습니다. 이 정보들은 훈련을 통해서 결정됩니다.
Hybrid Architecture.
Input sequence는 CNN의 feature map에서 추출 될수 있습니다. Hybrid model에서, patch embedding project은 CNN feature map에서 가져온 값에 사용됩니다.
Fine-Tuning and Higher Resolution
ViT를 large dataset에 pretrain 하고, smaller downstream task에 fine tuning을 합니다. Pre-trained prediction head는 제거하고, zero-initialized feed forward layer를 attach 합니다. Pretraining에서 사용한 해상도보다 fine tuning에서 더 높은 해상도를 사용하는 것이 더 유용합니다.
고해상도 이미지를 사용할때, patch size는 동일하게 유지합니다. 이는 effective sequence length를 더 길게 만들어 줍니다.
Vision Transformer는 다양한 길이의 sequence를 처리할 수 있습니다. 하지만, pretrained position embedding안 길이가 변하면 사용할 수 없습니다. 가려서 따로 original image의 position에 맞춰 2D interpolation을 해주어야 합니다.
이 interpolation은 유일한 manually injected inductive bias입니다.