SegNet : A Deep Convolutional Encoder-Decoder Architecture For Image Segementation
SegNet은 deep convolutional neural network으로 pixel-wise segmentation을 하기 위해 만들어졌습니다. SegNet은 Encoder와 Decoder로 이루어 져 있는데, Encoder의 구조는 VGG16을 기반으로 만들어졌습니다. Decoder는 Encoder를 뒤집은 모양이며, Maxpooling layer를 up-sampling layer로 변환한 것 입니다. 이때 max-pooling layer에서는 max-pooling 한 index들을 저장하고 그 값을 이용하여 up-sampling 합니다. 이러한 방식은 up-sampling을 Train하지 않아도 되기에 더 빠른 속도로 network를 train할 수 있습니다.
Introduction
SegNet은 pixel-wise semantic segmentation을 효율적으로 이용하기 위해서 만들어졌습니다. 이 인공신경망의 일차적인 목표는 도로 상황에 대한 이해 입니다. 도로와 빌딩을 구분하고, 자동차와 사람, 나무의 모양을 인식하며, 공간에 대한 이해(도로와 인도의 차이점)를 하기 위함입니다.
Architecture
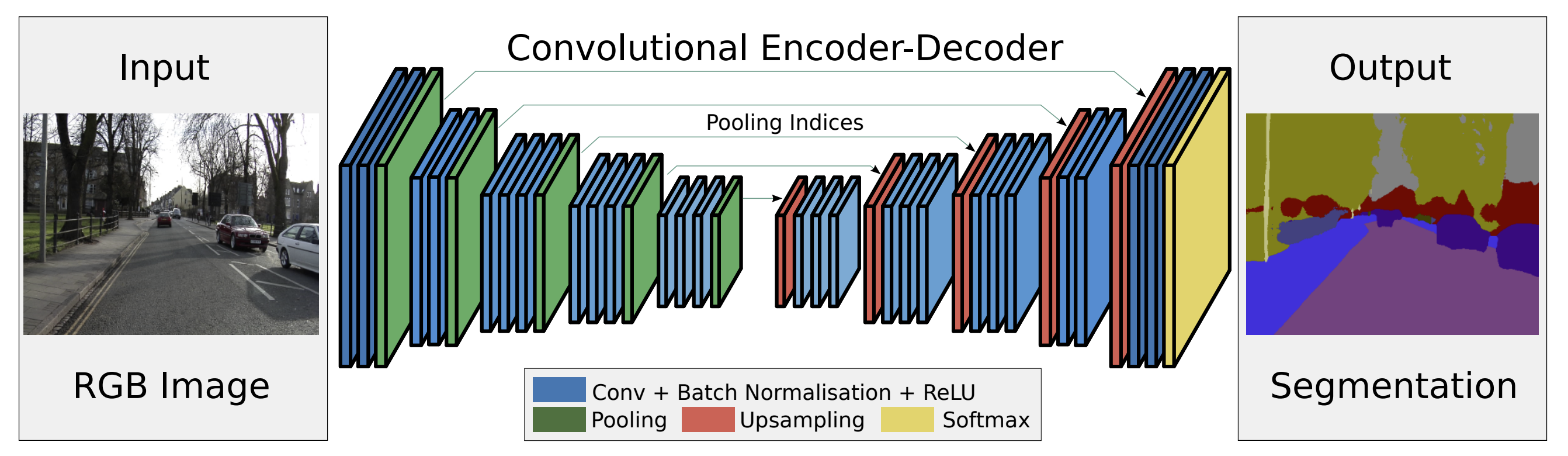
위 이미지는 SegNet의 구조를 표현한 것입니다. SegNet은 크게 encoder와 decoder 두가지 부분으로 나누어져 있습니다.
Encoder
SegNet의 Encoder는 13개의 Convolutional layer로 이루어져있습니다. 이 13개의 layer는 VGG16의 Convolutional layer와 똑같습니다. 하지만 VGG16에 있던 Fully connected layer를 제외하였는데, 이는 feature map의 높은 해상도를 위함입니다. 또한 Fully connected layer를 제거함으로 parameter 수가 급격하게 줄어들었습니다.
각 Convolutional layer가 끝난 다음에는 Batch-normalization layer와 RELU가 제공굅니다. Pooling layer는 Max-pooling을 사용하고, 이때 pooling한 index를 기억해 decoding stage에서 사용하게 됩니다.
Decoder
SegNet의 Decoder는 Encoder를 뒤집은 것과 똑같습니다. 차이점이 있다고 하면, max-pooling layer가 up-sampling layer로 바뀐것입니다.
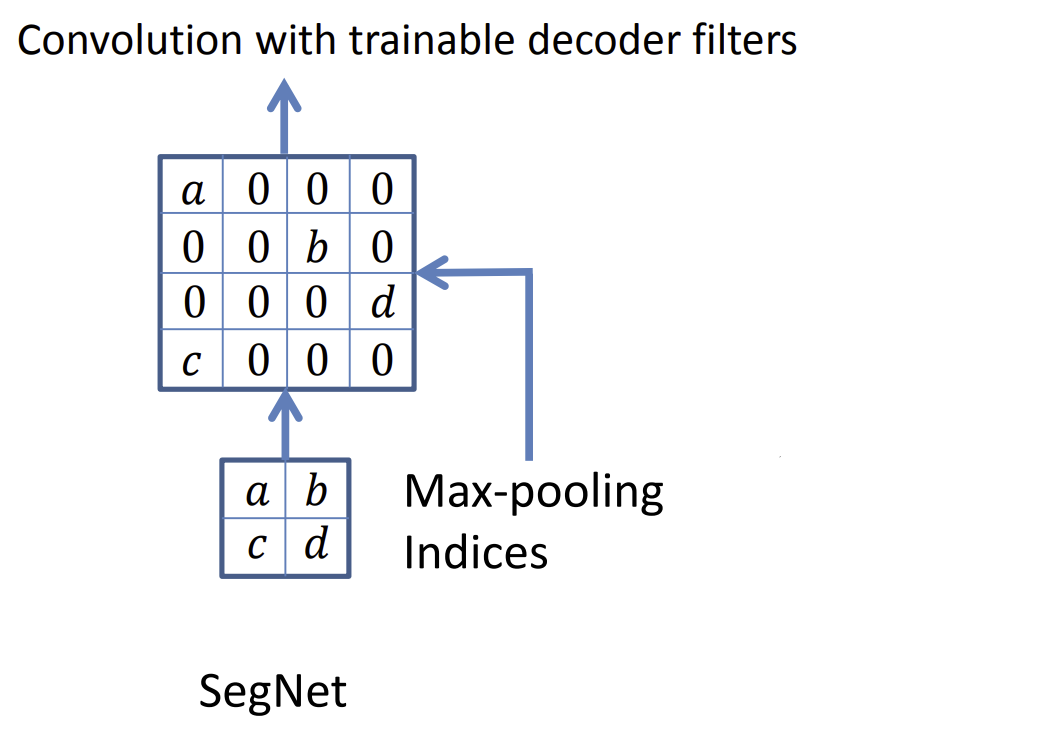
Up-sampling layer는 Max pooling layer에서 얻은 Index를 사용합니다. 이 Index를 사용해서 feature map을 늘리고, 비어있는 pixel에는 0을 기본값으로 설정합니다.
DeconvNet과 비교했을 때, SegNet은 Fully connected layer를 사용하지 않습니다. 그렇기에 SegNet은 더 적은 parameter수를 가지고 있고, inference time도 빠릅니다. 또한 DeconvNet과 SegNet은 비슷한 up-sampling layer를 사용합니다.
SegNet과 비교해서, Unet은 pooling indices를 사용하는 것이 아니라, feature map 전체를 저장합니다. 저장된 feature map은 deconvolution을 사용해서 얻은 feature map과 Concatenate 하여 convolution을 수행합니다.
Result
CamVid Result
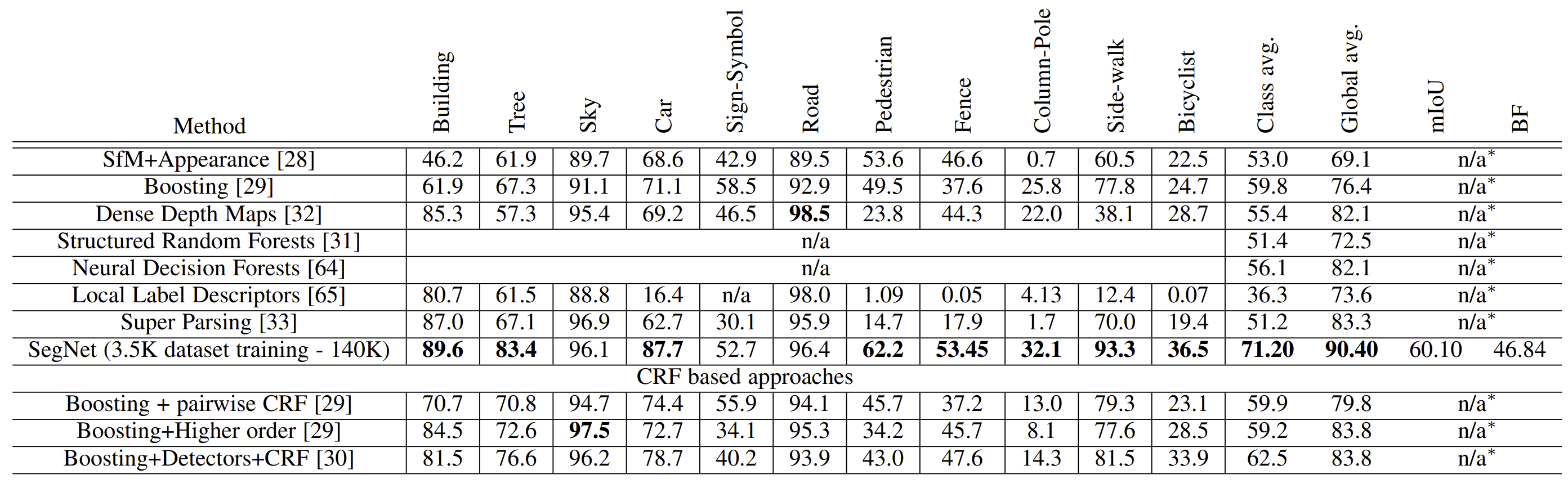
기존에 사용하던 전통적인 방법과 비교했을때, SegNet이 11개의 class 중 8개의 class에서 가장 높은 정확도를 보였습니다. 또한 global accuracy의 경우 가장 좋은 결과를 가지고 있습니다.

Deep learning 방법과 비교한다면, iteration이 증가할수록, SegNet이 더 좋은 결과를 보여줍니다.
SUN-RGBD indoor scene

Iteration이 작을 때 SegNet이 DeepLap과 비교했을때 Global accuracy와 BF에서는 우위를 점하지만, Class accuracy와 mIoU부분에서는 떨어집니다. 하지만 iteration이 140k 이상인 경우, SegNet이 mIoU를 제외하고는 모든 부분 에서 뛰어납니다.
Memory and Inference Time

DeepLap과 FCN은 SegNet보다 Inference Time이 빠른데 이는 DeepLap과 FCN이 decoder를 가지고 있지 않기에 발생하는 것입니다. 또한 DeconvNet과 비교했을때 SegNet는 Fully Connected layer를 가지고 있지 않기에 더 빠른 Inference time과 더 적은 memory를 사용합니다.