SegNet : A Deep Convolutional Encoder-Decoder Architecture For Image Segementation
SegNet is a deep fully convolutional neural network architecture for pixel-wise segmentation. SegNet consist of encoder and decoder. Encoder of the SegNet is topologically identical to VGG16 networks. Decoder is an mirror of the encoder. The max-pooling layer on encoder is changed to up-sampling layer using the indicies computed in the max-pooling layer. This eliminated the need of learning for up-sampling
Introduction
SegNet is designed to be an efficient architecture for pixel-wise semantic segmentation. The primary purpose of this network is to understand the road scenes, identify model appearance (roads, building) and shapes (car, pedestrians, trees), and understanding the spatial-relationship (context) between different classes, such as road, sidewalks, crosswalk, etc.
Architecture
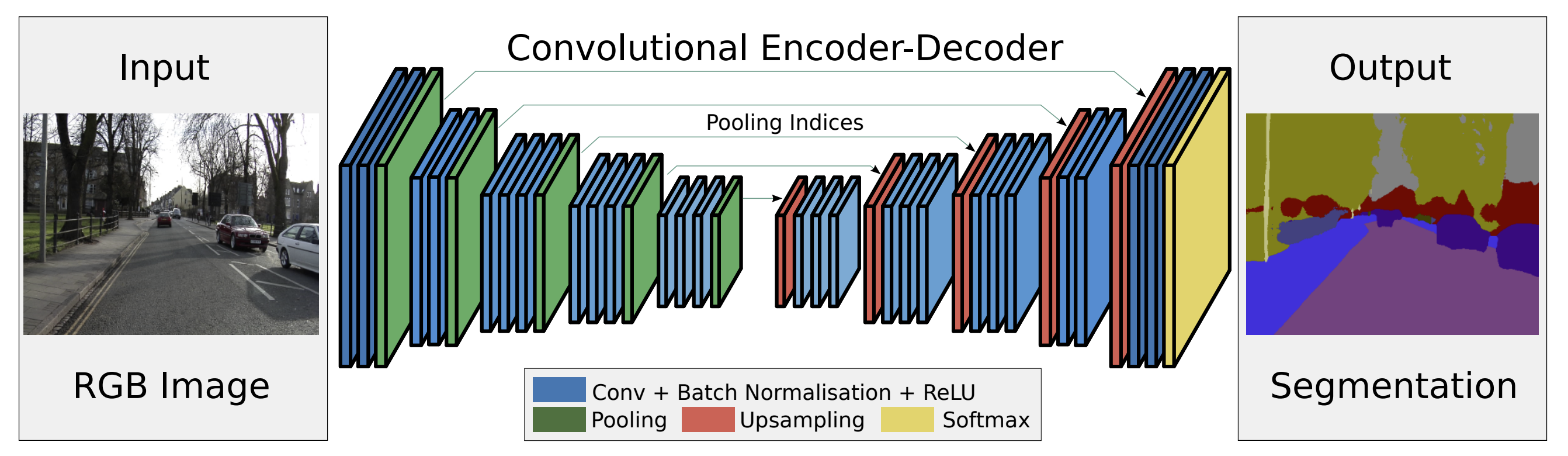
The above image is the architecture of the SegNet. SegNet consist of two different parts: Encoder and Decoder.
Encoder
The Encoder of SegNet consist of 13 convolutional layers that is identical to the convolutional layers in VGG16. From the VGG16, the fully connected layers are eliminated to retain the high resolution feature maps. Also, eliminating the fully connected layers decreased the number of parameters in the encoder of SegNet.
After each convolutional layer, batch-normalization and rectified linear non-linearity (max(x,0)) is applied. Pooling layer is consist of max-pooling with strides. In each pooling layer, pooling indicies are stored for up-sampling layer of decoder.
Decoder
The Decoder of SegNet are mirror image of Encoder. In the decoder, the max-pooling layer is subsituted with the up-sampling layer.
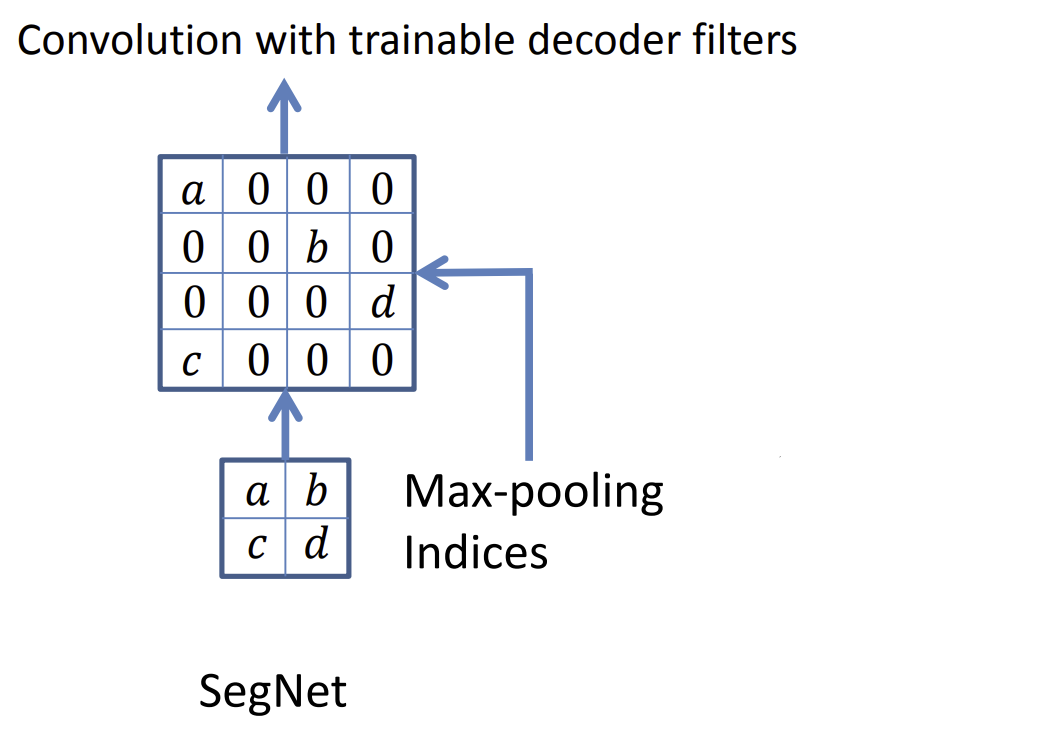
The upsampling layer uses the Max-pooling indices from the max-pooling layer. They use the indices to set the values retained from the previous layers. The values that are not marked by the max-pooling indicies are set to zeros.
Compared to DeconvNet, SegNet does not contain fully connected layer. Eliminating the fully connected layer, SegNet have much less parameters and faster inference time. SegNet and DeconvNet uses similar non-trained up-sampling layer.
Compared to SegNet, Unet does not use pooling indices, but instead they store full feature map and concatenates with the up-sampled feature map. The up-sampling in U-net is using deconvolution.
Result
CamVid Result
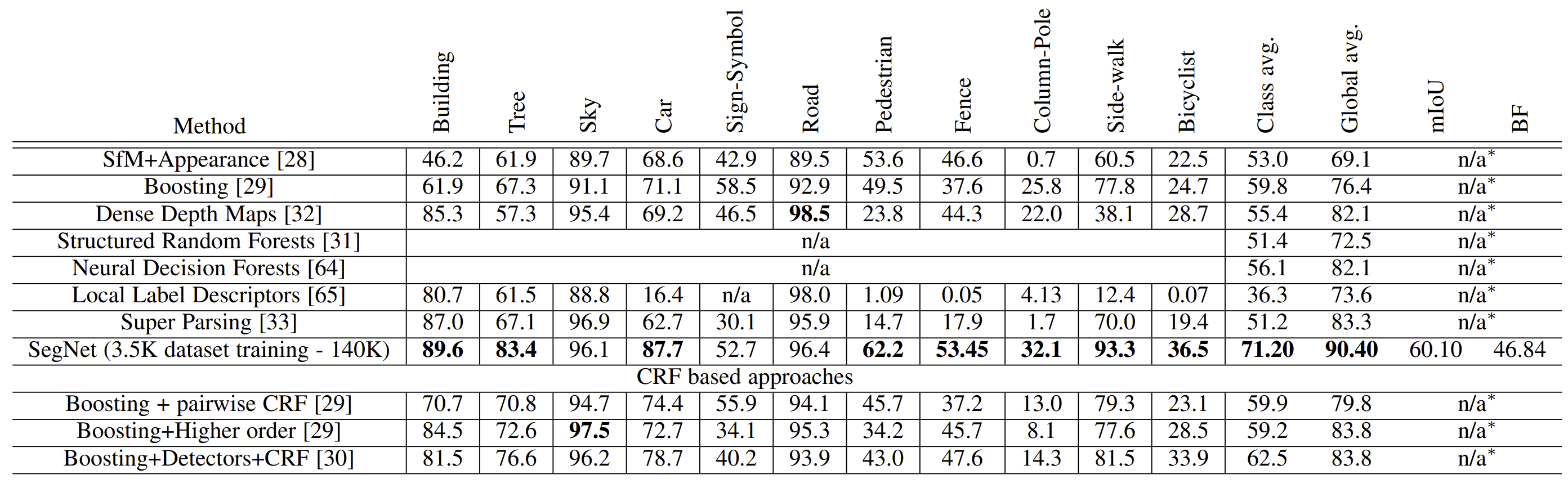
The result is from the paper. According to the paper, comparing with traditional methods, SegNet have highest accuracy in classifying 8 out of 11 classes. Moreover, the global average is the highest amonst different neural networks.

Comparing with deep learning methods, as the iteration increases, SegNet have highest values in Global accuarcy, Class average accuracy, mean of intersection Union and accuracy of inter-class boundary delineation.
SUN-RGBD indoor scene

The result is from the paper. SegNet have better global accuracy and BFs. DeepLab have better result in mIoU, Class average accuracy, when Iteration is less than 140k. However, when the iteration increases over 140k, SegNet have better result in Global accuracy, Class average accuracy and BFs.
Memory and Inference Time

As seen in the above table, DeepLap and FCN have faster inference time than SegNet because both network does not have decoder while SegNet have the decoder portion in the network. Compared to DeconvNet, SegNet does not have Fully Connected layer. Therefore, SegNet have faster inference time.