Aggregated Residual Transformations for Deep Neural Network
이 논문의 저자는 ResNet의 기본 단위인 Residual block을 Multi-branch를 활용하여 aggregated Residual block을 만드는 방식에 대해서 이야기합니다. 이러한 전략은 Neural Network에 새로운 차원을 소개하는데 저자는 이것을 Cardinality라고 명명했습니다.
Introduction
최근 visual recogntion에 관련된 연구를 살펴보면, 특징을 찾는 feature engineering에서 network enigneering으로 옮겨 가고 있습니다. 인공신경망이 발전해 가면서, Large-scale data을 기반으로 neural network를 통해서 feature을 찾을 수 있게 되었습니다.
좋은 안공신경망을 만드는 것은 레이어의 갯수가 증가할수록 hyper-parameter의 수가 늘어갈수록 만들기 어려워졌습니다. 여기서 hyper-parameter란 인공신경망을 훈련하기 위해서 조절하는 값들을 의미합니다. 예를 들어서 width, filter size, stride, depth 등이 있습니다. VGG network처럼 간단하면서 효율적인 전략을 사용하는 ResNet은 같은 모양읠 레이어를 쌓아가는 technique를 사용합니다.
이 논문은 VGG/ResNet의 전략은 반복적인 레이어를 사용하면서, 새로운 split-transform-merge 전략을 첨가했습니다. 이 전략은 Inception ResNet과 비슷하게 여러가진 branch로 나뉘어지고 마지막에는 합쳐집니다. 하지만 이 둘의 가장 큰 차이점은, Inception ResNet은 다양한 종류의 레이어를 사용하는것에 비해, ResNeXt리거 불리우는 이 네트워크는 같은 종류의 레이어를 연속적으로 사용합니다. 이를 통해서 network에 영향을 주는 factor들을 독립적으로 확인할수 있게 되었ㅅ브니다.
저자는 이 논문에서 새로운 방식인 cardinality를 강조합니다. Cardinality는 set of transofrmation의 크기입니다. 여러가지 실험을 통해서 저자는 cardinality를 늘리는 것이 network를 깊게하는 것이나 넓게 하는 것에 비해서 효과적이라고 말합니다.
Related work
Multibranch convolutional networks
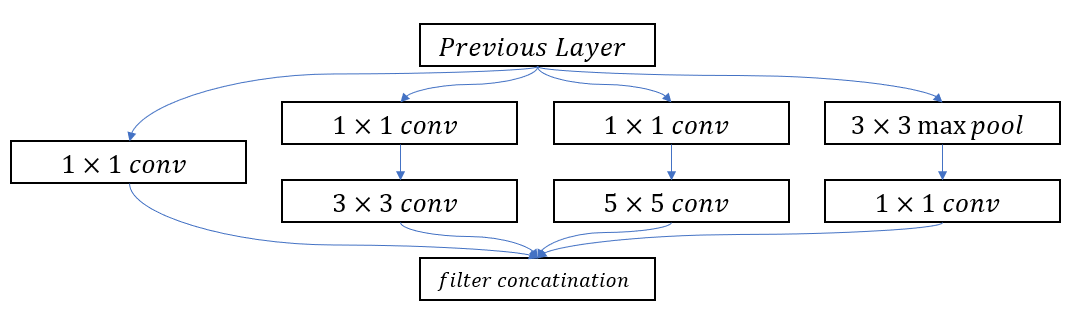
Inception model들은 성공적인 Multi-brach 구조들입니다. 모델안에 있는 각각의 가지들은 조십스럽게 조율되어 효과적인 neural network를 형성합니다.
| Inception module | Residual Module |
|---|---|
 |
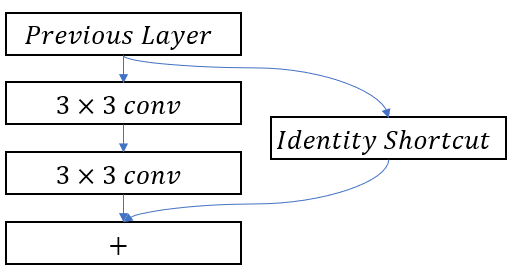 |
위의 이미지를 통해서 기본적인 Residual Module도 Multi-brach 모델임을 확인할 수 있습니다. 여기서 Residual network은 Identity matrix와 2개의 연속된 convolution레이어가 brach 이지만, Inception module의 경우 다양한 Convolutional layer가 여러가지 방면으로 뻗어 있는 것을 확인할 수 있ㅅ브니다.
Grouped convolutions
Group convolution은 AlexNet에서 부터 확인할 수 있습니다. 혹은 그 전에도 있었을 가능 성이 있습니다. 이러한 Group Convolution이 정확도를 올린 다는 것에 대한 연구는 진행되어 오지 않았습니다.
Compressing convolutional networks
Decomposition은 deep convolution network의 redundacy를 줄이기 위해서 널리 활용되는 기술입니다. 또한 이 기술은 deep convolutional network를 accelerate 하거나 compress 하기 위해서도 사용됩니다.
Ensembling
독립적으로 훈련된 신경망의 평균을 구하는 것은 정확도를 올리는 효과적인 방법증 하나입니다. 이러한 방법은 recognition 경쟁에서 활용중입니다. 하지만 ResNeXt는 이러한 ensemble 방법이 아닙니다. 왜냐하면 모든 weight 값들이 독립적으로 훈련된것이 아니라, 동시에 훈련되었기 때문입니다.
Method
Tempalate
ResNeXt의 구조는 모듈화 되어있는 VGG와 ResNet의 디자인으로부터 만들어졌습니다. 이 network들은 Residual block들로 이루어져있는데 모두 같은 형식이고, 두가지 간단한 법칙을 따르고 있습니다.
- Feature map의 크기가 같은 경우, 같은 갯수의 필터를 사용한다.
- Feature map의 크기가 반으로 줄어들었을 경우, 필터의 갯수를 두배로 늘리는 데, 그 이유는 모든 레이어의 시간복잡도를 동일하게 유지하기 위해서 이다.
이 두개의 법칙을 기반으로, 저자는 간단한 template를 만들었는데, 모든 network는 이 template을 기반으로 만들어집니다.
Revisiting Simple Neurons.
인공신경망에서 가장 간단한 형식의 뉴런을 살펴보면, 뉴런은 스칼라곱 연산을 합니다. 이때 이는 가장 기본적인 스칼라 곱을 합니다. 이는 Fully connected layers 와 convolutional layer에서 쓰는 base unit입니다.
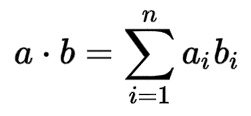
위의 수식은 aggregated Transformation이랑 비슷합니다. Aggregated Transformation은 아래의 식으로 확인 할 수 있습니다.
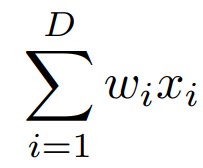
여기서 는 D-Channel 입력 백터이고
i-th Channel에 대한 필터의 weight 값입니다. 이 수식은 아래의 이미지와 같이 표한 될수 있습니다.
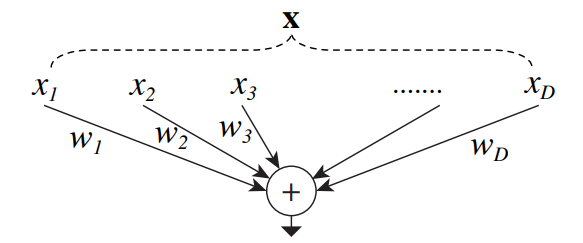
뉴런을 구성하는 연산은 3가지로 나누어 질수 있습니다:
- Spliting: vector 값 x 를 차원이 작은 subspace
들로 나눌 수 있습니다.
- Transforming : the low-dimensional representation 에 무게 값을 곱해줍니다.
- Aggregating : the transformations in all embedding are aggregated by
Aggregated Transformations
위에서 제공된 간단한 뉴런의 해석을 자세하게 살펴보면, Aggregated Transformation와 비슷한 형식으로 나타낼수 있습니다.
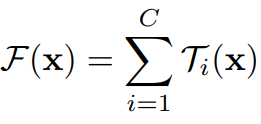
여기서 는 어떠한 함수를 사용해도 됩니다. Fully Connected layer는 물론 Convolutional layer도 괜찮습니다.
위의 수식에서 C는 Transformation을 할 set의 갯수를 의미하고 Cardinality라고 불리웁니다. 저 위의 수식 D과 같다고 해석할수 있습니다. 여기서 C의 값은 어떠한 양의 정수 값이라면 상관이 없습니다.
ResNeXt의 구조는 간단한 법칙에 의해서 지배됩니다. 모든 는 같은 형식으로 이루어 져야한다. 이 법칙은 VGG에서 볼수 있던 던 같은 레이어를 반복하는 것의 연장선입니다. 이러한 방식은 hyperparameter의 갯수를 줄여서 모든 요인들을 독립적으로 변환할수 있게 만듭니다. 게다가 간단한 형식으로 인해서 레이어를 깊게 만들거나 넓게 만드는 것이 쉽습니다.
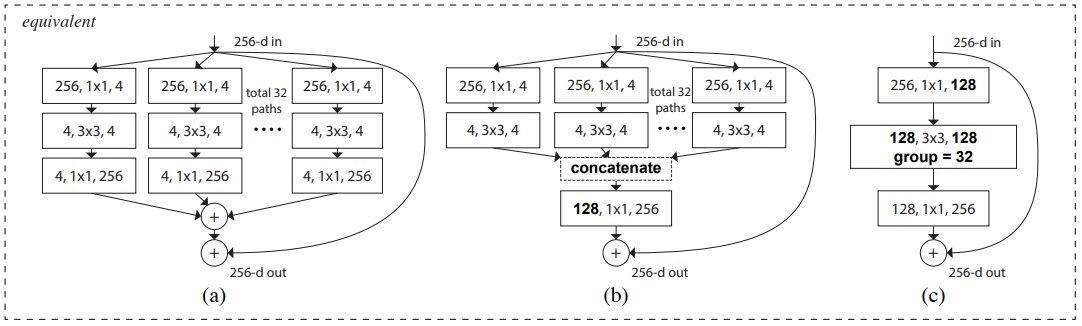
위의 이미지는 ResNeXt의 가장 기본적인 Block의 표현방식을 나타냅니다. 이 이미지에서 a)는 Aggregated Residual transformations, b)는 a)와 같지만 early concatenation을 활용한 것이고, c)는 a)와 b)에서 group convolution을 사용한 것입니다.
Relation to Inception-ResNet
ResNeXt는 Inception-ResNet block과 branching을 한다는 것에 비슷합니다. 하지만 둘의 가장 큰 차이점은 Inception-ResNet는 다양한 convolutional layers를 사용하는 것이고, ResNeXt 는 다양한 경로에도 같은 구조의 convolutional layer를 사용하는 것입니다.
Reference
https://takenotesforvision.tistory.com/12