Designing Network Design Spaces
이 논문의 목표는 인공신경망 설계에 대한 이해를 도우는 것과, 범용적인 환경에서 사용가능한 설계 원칙을 찾는 것입니다. 인공신경망 하나를 설계하는 것에 집중하는 것이 아니라 저자는 인공신경망 집합을 paramterize하는 network design space를 설계합니다.
Introduction
이 논문에서, 저자는 새로운 인공신경망 design paradigm을 소개합니다. 이 방식은 manual design의 장점과 인공신경망 탐색의 장점을 합쳤습니다. 인공신경망 하나를 설계하는 것에 집중하는 것이 아니라 저자는 인공신경망 집합을 paramterize하는 network design space를 설계합니다. Manual design 처럼, 저자는 해석가능성을 목표로 하고 있습니다. 이를 통해서 간단하며, 잘 장동하고, 모든 상황에서 사용가능 한 범용적인 design principle을 찾는 것을 목표로 합니다. 그리고 NAS 처럼 저자는 semi-automated procedure의 장점을 통해서 위의 목표를 이루려고 합니다.
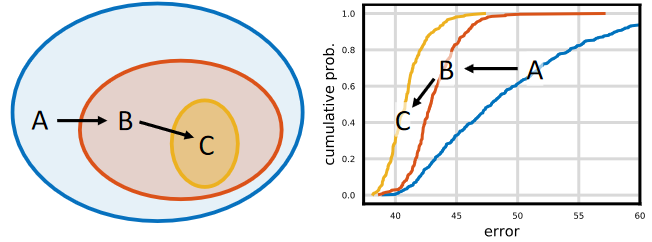
범용적인 전략은 성능을 유지시키거나 향상시키면서 초기의 design space에서 점진적으로 간단한 방식으로 설계를 하는 것입니다. 위의 이미지에서 보는 것처럼, 가장 초기의 design space A에서 두개의 개선방식을 적용시켜 design space B와 C를 얻었습니다. 이러한 경우, 이고, Error Dristribution이 A에서 B, B에서 C로 갈때 향상되는 것을 확인 할 수 있습니다. Model population에 적용된 design principle이 더 효과적이고 범용적이라는 희망을 가지고 있습니다. 전체적인 방식은 manual design과 비슷합니다. 다만 population level에 적용을 하고 network design space의 distribution estimate를 통해서 설명합니다.
이 논문의 주제는 인공신경망의 model family가 VGG, ResNet, ResNeXt를 포함하고 있다는 가정아래 network structure를 탐색하는 것입니다. 이러한 제약이 없는 design space를 AnyNet이라고 부르고, 이 AnyNet에 Human-in-the-loop 방식을 사용해서 low-dimensional design space에 도달한 network를 RegNet이라고 부릅니다. RegNet은 간단한 “regular” network로 이루어졌기에 그와 같은 이름이 붙었습니다.
Related Work
Manual Network Design
유명한 인공신경망, VGG, Inception, ResNet, ResNeXt, DenseNet, 그리고 MobileNet의 설계 방식은 대부분 수동이었습니다. 또한 정확도를 증가시키는 새로운 설계 방식을 찾기위해 집중했습니다. 저자는 이러한 인공신경망들의 목표인 새로운 설계 원칙을 찾는 것을 공유합니다. 이러한 방식은 manual design과 유사하지만 design space level에서 이루어집니다.
Automated network design
Network design process는 manual 탐색에서 NAS로 유명해진 automated network design으로 변화해왔습니다. 탐색 알고리즘에 집중하는 NAS와 다르게 이방식은 새로운 design space를 설계하는 방식에 집중합니다. 좋은 design space는 NAS 탐색 알고리즘의 효율을 높이고, design space의 질을 높임으로 더 좋은 모델이 있을 확율을 높여줍니다.
Comparing network
On network design space for visual recognition의 저자가 design space로부터 추출한 network의 집합을 비교하고 해석하는 새로운 방식을 소개합니다. 이 distribution-level의 관점은 범용적인 설계원칙을 찾는 것과 똑같습니다. 그럼으로 이 논문의 저자는 이 방식을 채용하고, distribution estimate가 design space를 설계하는 과정에서 유용한 도구가 될것이라고 설명합니다.
Parameterization
Final quantized linear parameterization은 이전 논문들과 비슷합니다. 하지만 중요한 2개의 차이점이 있습니다.
- design choice를 정당화 하는 empirical study를 재공합니다.
- 전에는 이해하지 못하는 structural design choice에 영감을 제공합니다.
Design Space Design
저자는 초기의 제한없는 design space로부터 점진적으로 간단하게 만드는 것을 제시합니다. 이를 Design space design이라고 말합니다. Design process의 각 단계는, initial design space를 입력값으로 수정한 design space를 출력값으로 여깁니다. 각 design step의 목표는 간단한 모델의 집합이나 더 좋은 성능을 가진 모델을 만드는 새로운 설계원칙을 찾는 것입니다.
Tools for Design Space Design
Design space를 평가하고 비교하기 위해 저자는 Radosavovic과 다른 저자들이 소개한 도구를 사용합니다. 이러한 방식은 design space에서 model의 집합을 추출하여 design space의 성능을 수치로 표현합니다. 그리고 구한 model error dsitribution을 characterize 하빈다.
Model의 distribution을 얻기위해서 저자는 design space로 부터 n개의 model을 sample하고 traniing 합니다. 효율성을 위해서 저자는 low-compute, low-epoch training 영역에서 사용합니다.
Deisgh space quality를 해석하기 위한 도구로 error empirical distribution function을 사용합니다. n개의 model에 대한 Error EDF를 error 를 사용해서 나타내면:
는 error가 e보다 작은 model의 부분을 나타냅니다.
위의 이미지는 n=500을 AnyNetX design space로 부터 추출한 error EDF를 나타낸 것입니다. 훈련된 model의 집합이 주어졌을 때, network properties와 network error사이의 관계를 그래프로 만들고 분석하였습니다. 이러한 모델의 시각화는 복잡하고 높은 차원의 정보를 1차원으로 줄여 design space에 관한 이해를 얻을 수 있도록 도와 줍니다.
요약하자면,
- model의 distribution은 design space로부터 n개의 model을 추출하고 훈련하여 얻습니다.
- Error EDF를 계산하고 그래프로 정리하여 design space quality를 요약합니다.
- design space의 다양한 특성을 시각화 하고 empirical bootstrap을 통해 insight를 얻습니다.
- 이러한 insight를 활용해 design space를 개선합니다.
The AnyNet Design Space
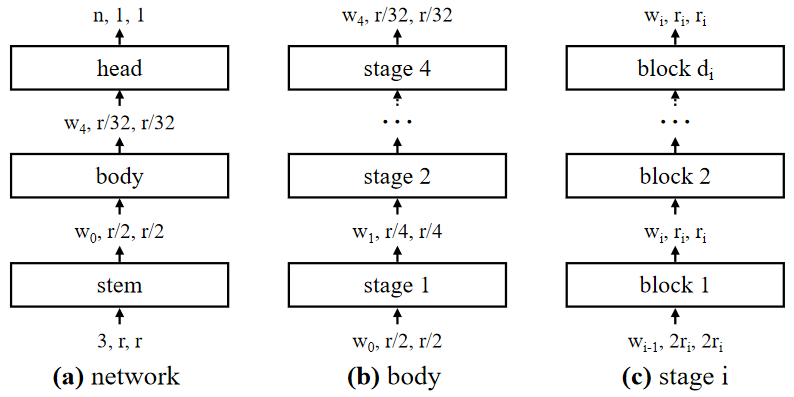
AnyNet design space의 기초적인 design은 아주 간단합니다. 위의 이미지에서 보는 것처럼, 입력 이미지가 주어졌다면, 인공신경망은, 간단한 stem, network body, 그리고 마지막으로 network head로 이루어졌습니다. Network body가 대부분의 연산을 실행하고, Network head가 마지막 출력 class를 예상합니다.
AnyNet의 network body는 점진적으로 작아지는 4개의 stage로 이루어졌습니다. 각각의 stage는 연속된 동일한 block으로 이루어져 있습니다. 전체적으로, 각각의 stage i에 대해서, degree of freedom은 number of blocks, block width, 그리고 다른 block parameter를 포함하고 있습니다.
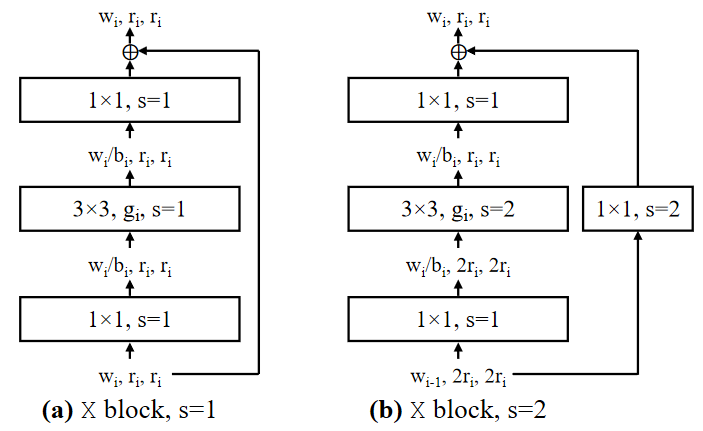
이 논문의 실험에는 기본적인 residual bottleneck block에 group convolution을 넣은 것을 사용합니다. 그리고 이 구조를 X block이라고 부릅니다. 위의 이미지에서 보는 것 처럼, 각각의 X block은 conv,
group conv and a final
conv로 이루어져있습니다.
convs가 channel width를 변화 시킵니다. 모든 convolution 뒤에는 Batch normalization과 ReLU 를 사용합니다. 이 Block에는 총 3개의 변수가 있습니다: the width
, bottleneck ratio
, and group width
.
X Block을 사용한 AnyNet을 AnyNetX라고 불리웁니다. 이 design space에서 16 degree of freedom이 있습니다. 총 4개의 stage에서 각각의 stage i가 4개의 parameter를 가집니다:
- the number of blocks
- block width
- bottleneck ratio
- group width
이러한 변수들을 조정해서 정확한 모델을 만든다고 가정을 한다면, 저자는 log-uniform random sampling을 ,
, and divisible by 8,
, and
에 적용합니다. 이러한 parameter를 사용해서 n=500이 되도록 추출을 하고 각 모델을 10epoch씩 훈련합니다.
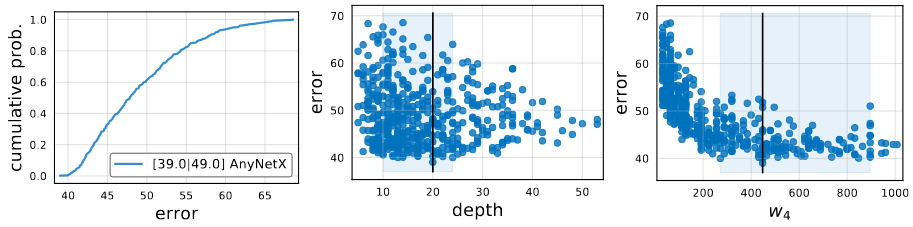
AnyNetX에 관한 기본적인 통계는 위의 이미지를 통해서 확인 할 수 있습니다.
위에서 제공한 parameter를 사용하면, AnyNetX의 design space에서 정확하게 개의 가능한 모델을 만들수 있습니다.
개도 넘는 모델에서 가장 좋은 model을 찾기보다, 저자는 design space를 설명하고 개선할 수 있는 범용적인 설계 원칙을 탐색합니다.
이러한 방식을 따르는 것에 4가지 목적이 있습니다.
- design space의 구조를 간단하게 만드는 것
- design space의 해석가능성을 향상시키는 것
- design space의 질을 유지하거나 향상시키는 것
- design space안에 있는 model의 다양성을 유지하는 것
AnyNetXA
가장 처음 사용하는 아무런 제약이 없는 AnyNetX design space를 AnyNetXA라고 합니다.
AnyNetXB
AnyNetXA의 design space에서 모든 stage i의 bottleneck ratio를 모두 동일하게 로 만드는 design space를 AnyNetXB라고 합니다. AnyNetXA처럼 AnyNetXB의 design space에서 500개의 model을 추출하고 훈련했습니다.
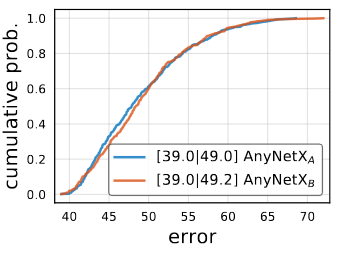
위의 이미지에서 보는 것 처럼, AnyNetXA와 AnyNetXB의 EDF가 거의 동일하다는 것을 알 수 있습니다. 이를 통해서 bottleneck ratio을 모든 block에서 동일하게 사용하는 것은 정확도에 아무런 영향을 주지 못하는 것을 알 수 있습니다.
AnyNetXC
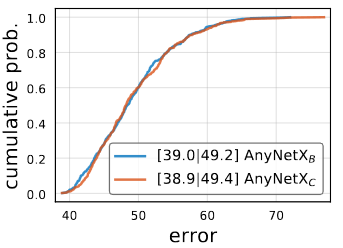
두번째 개선점은, 첫번째와 유사합니다. AnyNetXC는 AnyNetXB에 group width를 모두 동일하게 만든 것입니다. AnyNetXC와 AnyNetXB가 유사한 EDF를 가지고 있기에 정확도의 차이는 없습니다. 다만, degree of freedom이 6개 줄어들었고, 가능한 model의 수가 10000배 정도 줄어들었습니다.
AnyNetXD
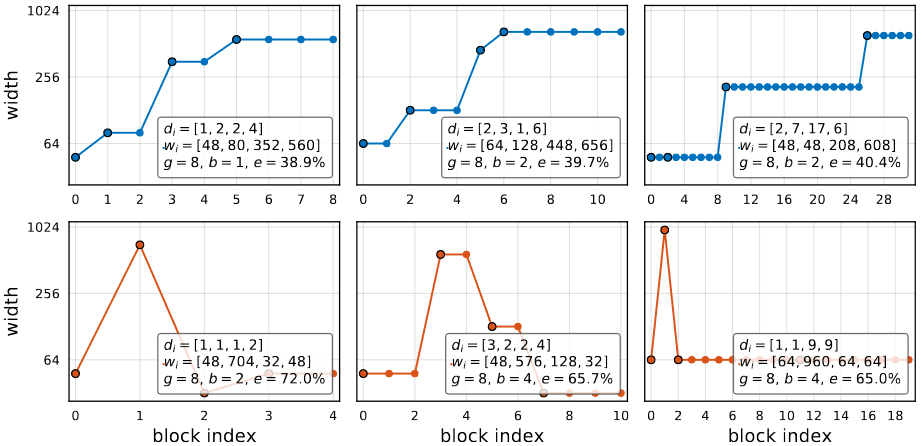
AnyNetXC의 network structure중에서 좋은 결과를 낸 network와 나쁜 결과를 낸 network의 구조를 표현한 이미지가 위에 있습니다. 위의 3개의 그래프가 좋은 결과를 낸 network structure이고 밑의 3개가 나쁜 결과를 낸 network structure입니다.
이 그래프를 통해서 한가지 pattern을 확인할 수 있습니다. 좋은 인공신경망의 경우 width가 증가하는 것을 알 수 있습니다. 이 설계 원칙, 를 AnyNetXC에 적용한 것이 AnyNetXD입니다.
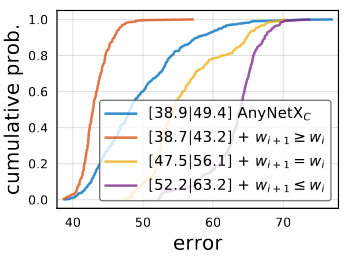
이 그래프가 width에 여러가지 제약을 준 상태의 결과를 나타낸 것입니다. width가 증가할경우, AnyNetXD의 design space를 사용할 경우, EDF가 상당히 증가하는 것을 확인 할 수 있습니다.
AnyNetXE
또 다른 공통적인 페턴이 있습니다. Stage의 깊이 가 마지막 레이어를 제외하고 대체적으로 증가하는 추세를 가지는 것을 알 수 있습니다.
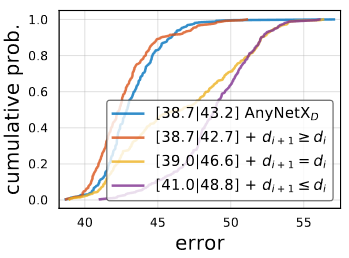
AnyNetXD에 를 적용한 것을 AnyNetXE라고 합니다. AnyNetXE가 AnyNetXD보다 살짝 더 좋은 결과를 가지고 있습니다.
와
의 제약을 주는 것은 가각 design space를 4!만큼 줄입니다. 전체적으로 AnyNetXE는 AnyNetXA 보다
만큼 design space의 크기가 작습니다.
The RegNet Design Space
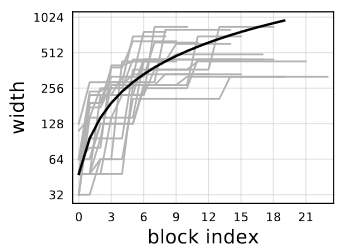
위의 이미지는 AnyNetXE에서 가장 좋은 결과를 낸 20개의 모델을 하나의 그래프에 나타낸 것입니다. 각각의 model 마다, j block에 per-block width 를 깊이 d 만큼 가지고 있다고 가정합니다. 여기서 각각의 model은 다양하게 존제합니다(회색선). 모든 모델들의 network width의 성장을 설명하는 하나의 수식(
, black solid line)이 존재합니다. 여기서 y축은 logarithmic입니다.
모든 모델이 quantized width(부분선형함수)임으로, 저자는 block width를 위한 linear parameterization을 소개합니다.
위의 수식에서 나오는 3개지 변수는 depth , initial width
, and slope
입니다. 위 수식을 사용해서
인 block들의 block width
를 구할 수 있습니다.
를 quantize 하기 위해서, 저자는 새로운 변수
를 소개합니다. 이변수를 사용하는 방법은 아래와 같습니다. 첫번째로, 위에서 얻을 수 있는
를 기반으로
를 구합니다. 이때 다음과 같은 수식을 적용가능해야합니다.
를 quantize하기 위해서는
를 반올림하는 것입니다.
라는 수식으로 표현됩니다. 그리고 이를 통해서 quantized per-block widths
는 아래와 같은 수식으로 정리합니다.
위의 수식은 per-block 형식으로 만들어진 것입니다. per-stage형식으로 변환하는 것은 아주 간단합니다. 첫번째로 로 변화시키는 것이 가장 처음이고 다음으로는 block의 개수를
을 이용해서 구하는 것입니다.
저자는 이 parameterization 방식을 AnyNetX 모델에 적용시켜 사용가능한 것인지 실험해보았습니다. 각각의 모델에 대해서 d를 network depth로 고정하고 grid seach를 사용해서 mean log-ratio(denoted by )를 최소화 하는
,
, and
를 구하는 것입니다.
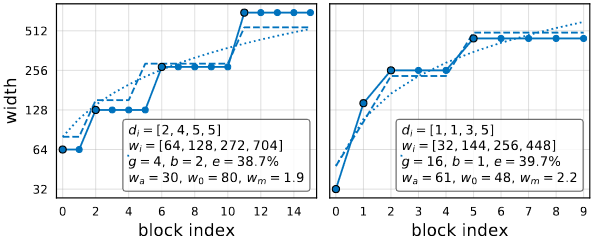
위의 이미지는 AnyNetXE의 가장 결과가 좋은 두개의 인공신경망입니다. 여기서 점선은 quantized linear fit이고 실선은 그들이 가지고 있는 가장 좋은 결과를 의미합니다.
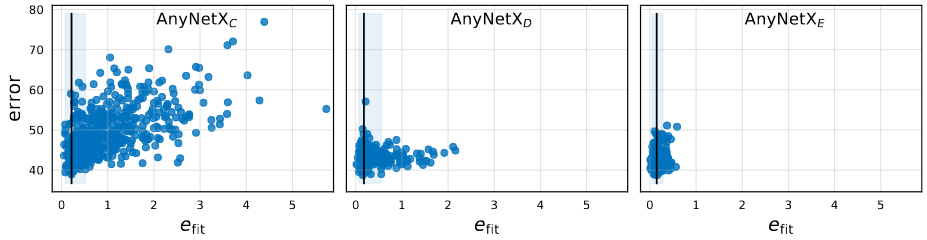
fitting error 와 network error의 관계를 그래프로 표현한 것입니다. 이 이미지로 부터 두가지 관측된 결과가 있습니다.
- 좋은 결과를 가진 model은 모두 좋은 linear fit을 가지고 있습니다.
- 평균적으로,
은 AnyNetXC에서 AnyNetXE로 갈때 증가합니다.
Linear parameterization을 실험하기 위해서 저자는 linear parameterization만을 사용하는 design space를 설계했습니다. 이 인공신경망은 총 6개의 parameter(d, ,
,
, b, g)로 구성되어 있습니다. 이러한 변수들을 사용해서 block width와 depth를 위의 수식들을 이용해서 구합니다. 이러한 형식으로 정해진 design space를 저자는 RegNet이라고 정의 했습니다. 이때 parameter들은
에서 선택하였습니다.
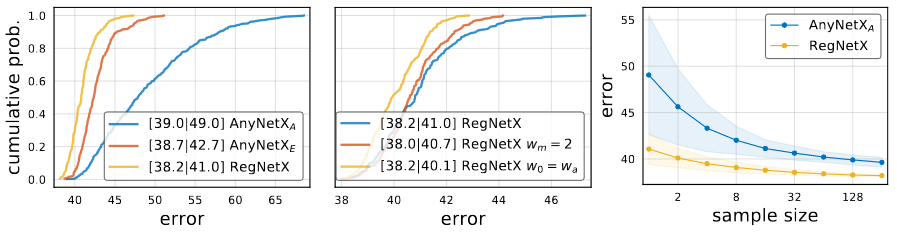
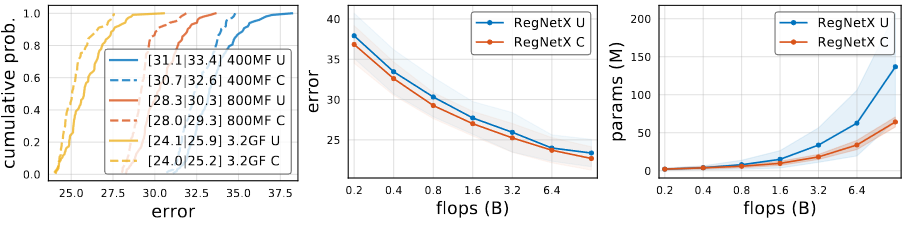
RegNetX의 error EDF는 가장 왼쪽의 이미지에서 확인 할 수 있습니다. RegNetX의 모델은 AnyNetX의 모델보다 평균적으로 좋은 결과를 가지고 있습니다. 중간의 이미지는 두개의 제약을 더한 RegNet의 error EDF입니다. 첫번째는 이고 두번째는
입니다. 하지만 design space내의 model의 다양성을 유지하기 위해서 저자는 이러한 제약사항을 사용하지 않았습니다. 마지막이미지는 random search efficiency를 나타낸 것입니다.
Design Space Summary

위의 이미지는 design space의 크기를 정리한 것입니다. RegNet의 경우, 연속된 변수의 paramterization의 크기로 예측값을 구한 것입니다. RegNetX를 디자인하는 데 저자는 AnyNetXA design space로 부터 16개의 dimension로부터 6개로 줄였습니다. 전체적인 design space의 크기는 10자리 정도 줄였습니다.
Design Space Generalization
RegNet design space는 low-compute, low-epoch, 그리고 단일 block type으로 설계되었습니다. 저자는 자신이 제시한 원칙이 다른 환경에서도 적용하는 지 확인을 하기 위해서, 높은 flops, higher epoch, 5-stage와 다양한 block type을 사용해서 설험했습니다.
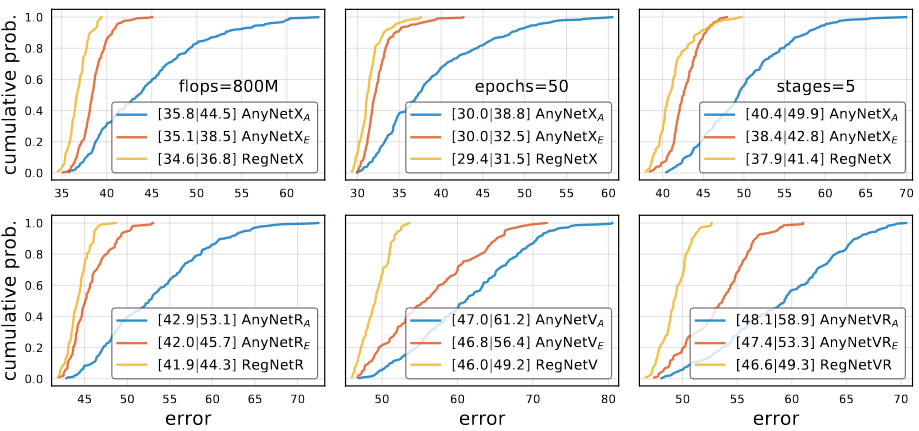
모든 환경에서 design space의 성능은 항상 로 똑같습니다. 다른 말로 하면, overfitting은 일어나지 않았습니다. 5-stage의 실험의 경우, RegNet의 결과가 더 많은 stage에도 사용 가능한 것이라고 알려줬습니다. 이 경우에 AnyNetXA는 더 큰 design space를 가지게 됩니다.
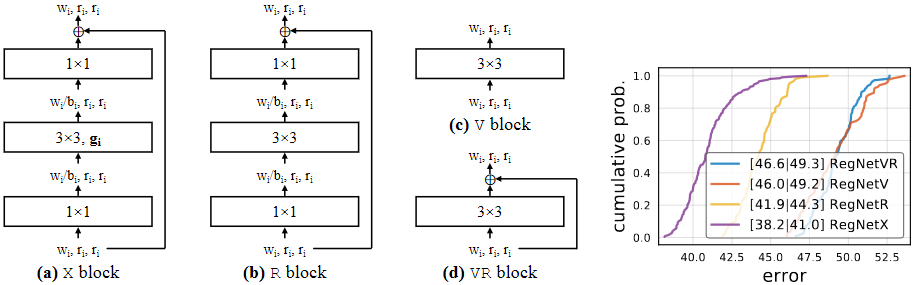
위의 이미지는 이 test에서 사용한 다양한 block의 구조를 표현한 것입니다. 여기서 X block이 가장 좋은 결과를 가지고 있는 것을 확인 할 수 있습니다.
Analyzing the RegNetX Design Space
저자는 RegNetX design space를 자세하게 연구하고 많이 사용하는 deep network design choice를 다시 한번 확인합니다. 이러한 연구를 통해서 사용되고 있는 것과는 다른 결과를 확인 할 수 있습니다. RegNetX의 design space는 좋은 model이 많기 때문에 sample의 수를 더 줄였고 대신 더 긴 epoch동안에 훈련을 하였습니다.
RegNet trends
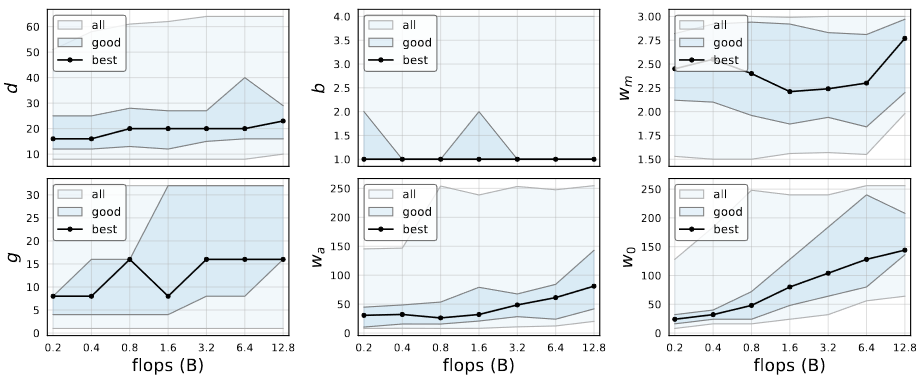
- 가장 좋은 model들의 깊이는 대부분 비슷했고 대체적으로 20개 내외의 block을 가지고 있습니다.
- 깊이가 깊으면 더 좋은 결과를 낸다고 알고 있는 것과는 다릅니다.
- Bottleneck ratio가 1일때의 결과가 가장 좋았습니다.
- 이는 Bottleneck을 없에는 효과가 있습니다.
- Width multiplier
는 대체적으로 2.5정도 입니다.
- 많이 사용하는 width를 2배로 늘리는 것과 비슷합니다.
- 다른 변수들은 complexity가 증가하면 같이 증가합니다.
Complexity analysis
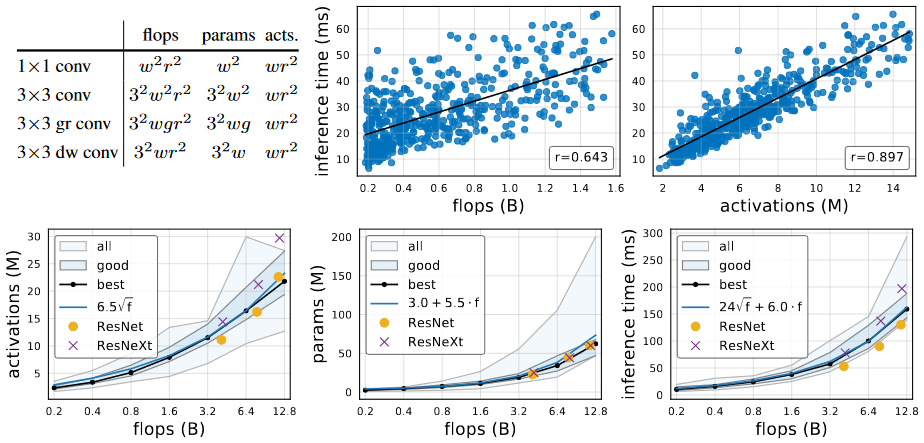
Flops와 parameter를 사용하는 것과 동시에, 저자는 새로운 complexity metric인 network activation을 소개합니다. network activation은 모든 convolution 연산의 출력 tensor의 크기를 더한 것입니다. 연산을 하는 방식은 위에 표에 적혀져 있습니다. Activation을 사용하는 것은 특이한 방식이지만, memory가 제약된 상황에서 runtime에 영향을 많이 미칩니다. 오른쪽 위의 이미지를 통해서 확인 할 수 있습니다.
가장 좋은 결과를 낸 model의 집합에서 activation은 flops의 제곱근에 비례하여 증가합니다. parameter의 경우 linear하게 증가하고, runtime은 linear와 동시에 제곱근에 비례합니다. 다른 말로, runtime은 activation과 flops에 의존합니다.
RegNetX constrained
위에서 발견한 사실들을 가지고 RegNetX의 design space에 제약을 가합니다.
- RegNet trend에서 확인 한 사실을 가지고,
,
와
를 적용합니다.
- Complexity analysis에서 확인 한 것을 통해서 parameter와 activation을 제약합니다.
- 이는 정확도의 손실 없이 빠르고, low-paramter에 low-memory인 모델을 찾도록 도와줍니다.
제약을 가한 RegNetX를 RegNetX C로 표현을 하고, RegNetX C의 결과는 모든 상황에서 더 좋은 정확도를 가지고 있습니다.
Alternate Design Choices
Mobile Network는 Inverted Bottleneck()과 depthwise convolution(
)을 사용합니다.
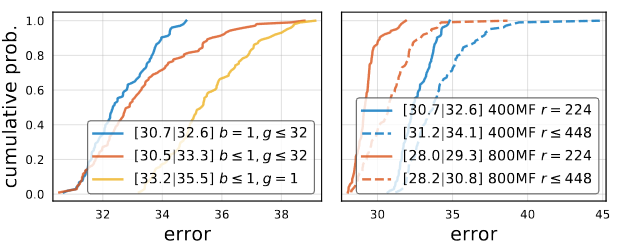
결과를 확인해 보면, inverted bottleneck의 경우 EDF가 살짝 줄어드는 것을 볼 수 있습니다. 하지만 Depthwise convolution의 경우, 심각할정도로 많이 줄어듭니다. 오른쪽 이미지에서 보는 것 처럼, 이미지의 해상도를 변화시키는 것은 성능 향상이 일어나지 않습니다.
SE
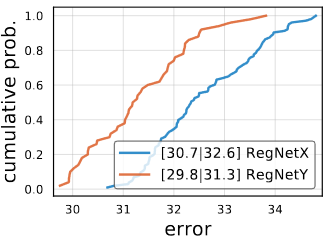
RegNetX에 유명한 Squeeze and excitation연산을 추가 한 것을 RegNetY라고 부릅니다. RegNetY는 RegNetX보다 좋은 성능을 가지고 있습니다.
Comparison to Existing Networks
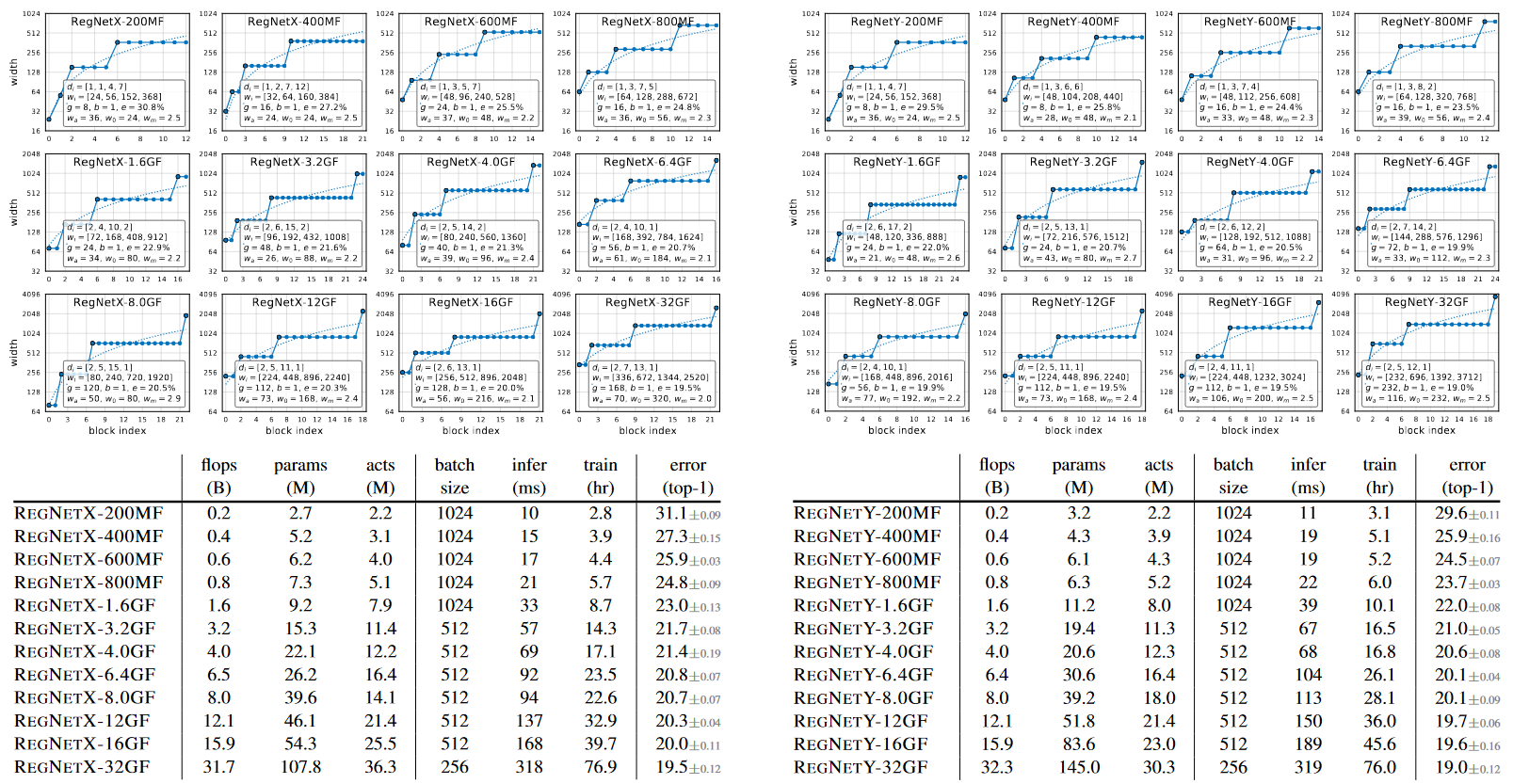
위의 그래프는 가장 좋은 RegNetX와 RegNetY model을 각 flops 영역에서 나타낸 것입니다. 위에서 보인 Linear structure 그래프를 확인하면 신기한 pattern을 확인 할 수 있습니다. FLOP이 크면, 세번째 stage에 있는 block의 수가 많아지고 마지막 stage의 수는 아주 ㅁ낳이 작아집니다. Group width d 는 FLOP이 커지만 같이 커지지만, depth d는 큰 모델에서 더 커지지 않습니다.
State-of-the-Art Comparison: Mobile Regime
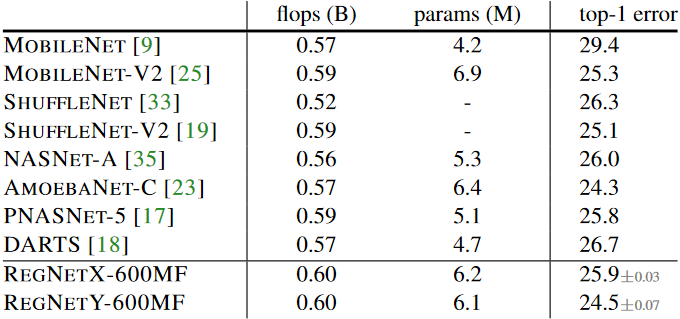
최근 몇년간의 network design은 mobile 환경에 집중을 해왔습니다. 그래서 그런 network들과 비교하기 위해서 600MF RegNetX와 RegNetY 모델을 비교합니다. RegNet 모델들이 더 효과적이라는 것을 알 수 있습니다. 왜냐하면 RegNet모델들은 100epoch정도 밖에 training을 하지 않았고 별다른 regulartization(weight decay을 제외한)을 사용하지 않았습니다. 또한 RegNet을 찾는데 걸리는 시간이 다른 manual design이나 NAS를 사용한 것보다 더 시간이 적게 걸렸기 때문입니다.
Standard Baselines Comparison: ResNe(X)t
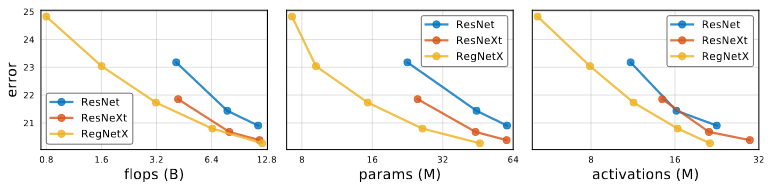
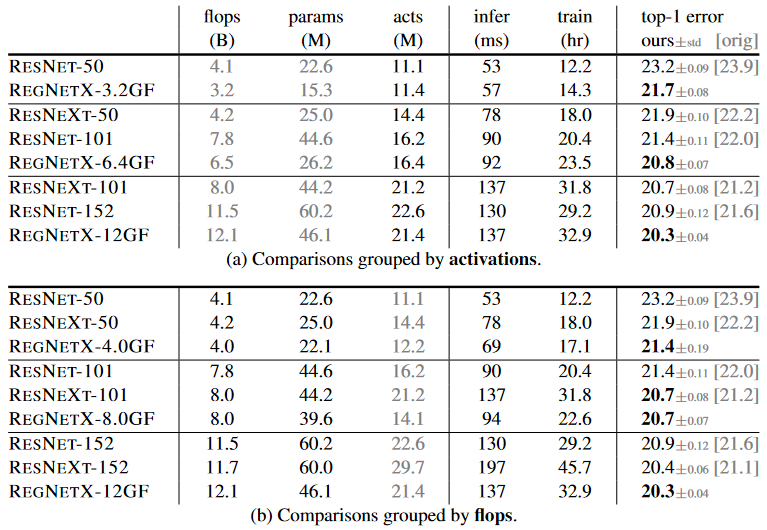
RegNetX는 ResNe(X)t에 비해서 모든 complexity metrics에 대항하여 더 좋은 결과를 가지고 있습니다.
State-of-the-Art Comparison: Full Regime
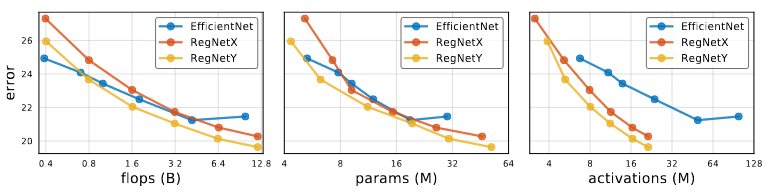
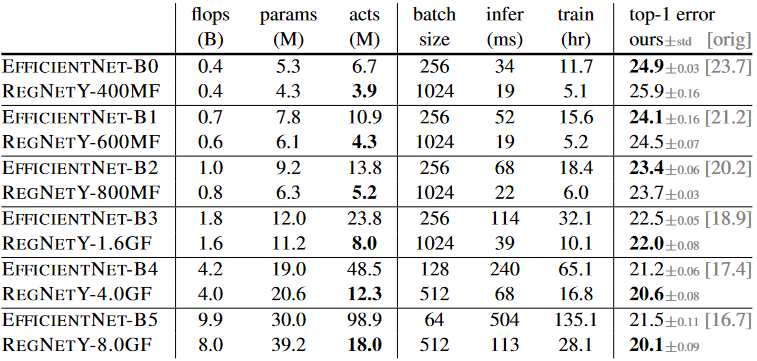
RegNet을 훈련할때 사용하는 setting을 그대로 사용해서 EfficentNet을 훈련시켰습니다. 그래서 논문에서 나온 것보다는 정확도가 떨어지는 것을 알 수 있습니다.
Flop이 작은 모델의 경우 EfficentNet이 더 좋은 결과를 보여줍니다. 하지만, 중간 FLOPS의 경우 RegNetY가 EfficentNet보다 더 좋은 결과를 가지고 있고, FLOPS가 높은 경우 RegNetX와 RegNetY모두 EfficentNet보다 더 좋은 결과를 가지고 있습니다.
또한 EfficentNet의 activation은 Flops와 linear하게 증가하는데 RegNet의 경우 square-root에 비례하게 증가합니다. 그렇기에 EfficentNet은 Inference와 Training time이 RegNet보다 느립니다.
Conclusion
저자는 새로운 network design 방식을 소개합니다. Designing network design space는 미래 연구를 위한 유방한 방안입니다.