MobileNetV2: Inverted Residuals and Linear Bottlenecks
이 논문에서 저자는 새로운 mobile architecture, MobileNetV2를 소개합니다. MobileNetV2는 전 모델보다 다양한 테스트 환경과 밴치마크에서 더 좋은 실적을 냅니다.
Introduction
인공신경망은 다양한 분야의 기계학습에서 대혁명을 일으켰습니다. 이미지 인식 과제에서는 이미 인간의 인식률을 뛰어넘었습니다. 이러한 정확도의 증가는 다양한 비용을 기반으로 만들어졌습니다. 최첨단 인공신경망은 빠른 연산을 할수 있는 기기가 필요합니다. 이러한 연산제한때문에 휴대용 기기나 임베디드 기기에서는 사용을 할수가 없습니다.
이 논문에서는 새로운 인공신경망구조를 소개합니다. MobileNetV2라고 불리우는 이 신경망은 휴대용기기와 리소스가 제한된 환경에 적합하도록 만들어진 구조입니다. 연산량과 메모리 사용량을 줄이면서, 비슷한 성능을 내기위해, 저자는 inverted residual with linear bottleneck이라는 새로운 레이어 모듈을 소개합니다
Related Work
현재 인공신경망의 구조에 대한 알고리즘적 해석의 탐색에 많은 진전이 있었습니다. 이러한 진전들은 hyperparameter 최적화, 다양한 방식의 network pruning, 그리고 connectivity learning이 있습니다. 이러한 연굴들이 convolution block 내의 connectivity 구조를 변화시켰습니다.
최적화를 하는 다른 방법으로는 유전 알고리즘을 사용하는 방식과 강화학습을 통한 구조 탐색이 있습니다. 하지만 이러한 방식의 단점은 인공신경망의 크기가 커진다는 것입니다.
이 논문에서 사용한 인공신경망의 다자인은 MobileNetV1에 기반합니다.
Preliminaries, discussion and intuition
Depthwise separable convolution
Depthwise Separable Convolution은 효율적인 인공신경망을 만드는 데 필요한 기본 요소입니다. 이는 full convolutional operator를 분해하여 두개의 레이어로 만듭니다.
- Depthwise convolution
- pointwise convolution
자세한 내용인 링크를 확인해 주시기 바랍니다.
Linear Bottlenecks
깊은 인공신경망에 N개의 레이어가 있다고 가정합시다. 레이어 는 각각
의 activation tensor로 구성되었습니다. 이러한 activation layer들의 집합은 manifold of interest를 구성합니다. Manfold of interest는 low-dimensional subspace에 내장되어 있습니다. 다른 말로 하면 deep convolutional layer의 d-channel pixel들에 암호화되어 있는 정보는 실질적으로 어떠한 mainfold 안에 저장되어 있습니다. 이는 low-dimensional subspace에 내장 가능합니다.
보편적으로 layer transformation 의 결과가 non-zero volume
를 가진다면,
안으로 투영된 point는 linear transformation
의 입력값을 통해서 구할수 있습니다. 이를 통해서 전체 출력값에 대응하는 입력값의 한 부분은 linear transformation으로 제한됩니다. 다른 말로 하면, 깊은 인공신경망은 출력의 non-zero volume에 대한 linear claissifier의 지수로 표현됩니다.
다른 한편으로, ReLU가 Channel을 압축하게되면, 그 Channel의 정보는 필연적으로 소실되게 됩니다. 하지만 채널의 수가 많다면, activation manifold가 정보를 보존하고 있을 가능성이 있습니다. 아래의 이미지가 이를 설명합니다.

이 예제에서, 가장 첫번째 나선은 n 차원 공간에 내장되어 있습니다. 이를 무작위 적인 행렬 를 곱하고 ReLU를 사용한 다음 역행렬인
를 사용해 다시 2D이미지로 변환한 것입니다. 여기서
일때 정보의 손실이 생겨 몇몇부분에는 하나의 선으로 변환 된 것을 확인할수 있습니다. 하지만
와 30일때에는 정보의 손실이 적어 입력값과 비슷한 이미지가 나옵니다.
요약하자면, manifold of interest가 higher-dimenstional activation space 안에 있는 low-dimensional subspace에 존재하기 위한 두가지 특성은 :
- Manfold of interest가 ReLU transformation 후에 non-zero volumne에 남아있다면, 이는 Linear transformation으로 볼 수 있다.
- 만약 input manifold가 입력 공간 내에서 low-dimansional subspace에 존재한다면, ReLU가 input manifold에 관한 정보를 손실없이 보존할수 있습니다.
Manifold of interest가 low-dimension이라면, linear bottleneck layer를 convolutional block에 삽입하여 manifold of interest를 추출할수 있다. 실험을 통해서, linear layer 를 사용하는 것이 non-linearity가 정보를 소실 시키는 것을 방지 할수 있다.
Inverted residuals
Bottleneck 구조가 모든 정보를 보존한다는 사실로부터 착안하여 skip connection을 bottleneck 구조 사이에 만들었습니다. 여기서 expansion layer는 non-linear transpormation을 적용하기 위한 implementation deatil입니다.
| Residual block | Inverted Residual Block |
|---|---|
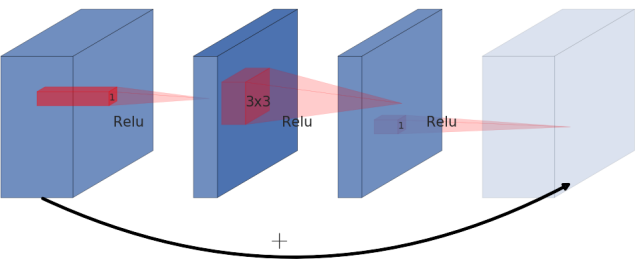 |
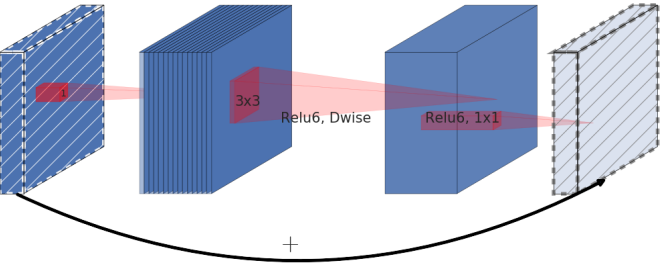 |
Residual Block은 보통 왼쪽의 이미지로 표현됩니다. 이미지에서 표현된것 처럼 wide -> narrow -> wide 의 형태로 bottleneck구조를 만들었습니다. 하지만 이 논문에서, 저자는 inverted residual을 제공합니다. 오른쪽의 이미지처럼 narrow -> wide -> narrow의 구조를 채택했습니다. 사선으로 표현된 부분은 non-linearlities를 사용하지 않습니다. 이는 non-linearlity를 사용해서 생기는 정보손실을 줄이기 위함입니다.
Inverted residual block에서 사용하는 skip connection은 ResNet에서 사용 하는 것과 같습니다. 이는 여러개의 레이어를 사용함에도 gradient가 vanishing하는 것을 방지하기 위함 입니다.
Inverted Residual block은 메모리 사용량도 적고, 성능도 더 좋습니다.
Running time and parameter count for bottleneck convolution

위의 표는 inverse residual function의 가장 기본적인 구조를 나타낸 것입니다. 위의 입력값에서 는 이미지의 크기,
는 커널 사이즈,
는 expansion factor,
와
는 각각 입력채널의 수와 출력채널의 수 입니다. 이 값들을 사용해서 multi-add의 갯수를 구하면 아래와 같습니다.
이 숫자는 depthwise separable convolution(이 링크에서 설명된)의 연산량보다 높습니다. 이는 추가적으로 들어간 convolution layer 때문입니다. 하지만, 입력과 출력의 차원이 depthwise convolution layer 보다 작기 때문에, bottleneck residual block의 전체적인 연산량은 작아집니다.
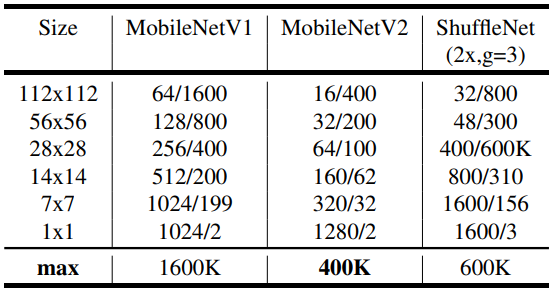
위의 표에서 확인 할수 있습니다. 여기서 표현된 숫자들은, channel의 숫자/memory의 량을 적었습니다. 16bit float를 사용한다고 가정했을 때의 memory 사용량입니다. 여기서 MobileNetV2가 가정 적은 매모리를 사용합니다. ShuffleNet의 크기는 2x, g=3를 사용했는데, 이는 MobileNetV1과 MobileNetV2와의 성능을 맞추기 위함입니다.
Model Architecture
Building block에 관한 자세한 설명은 위에 적혀져 있습니다 Detailed information about the building block is describe above.
MobileNetV2의 구조는 가본적으로 32개의 필터를 가진 Fully convolution layer로 시작합니다. 이후로 19개의 residual bottleneck layer를 가지고 있습니다. 아래에 표를 확인하면 MobileNetV2의 구조를 확인할 수 있습니다.
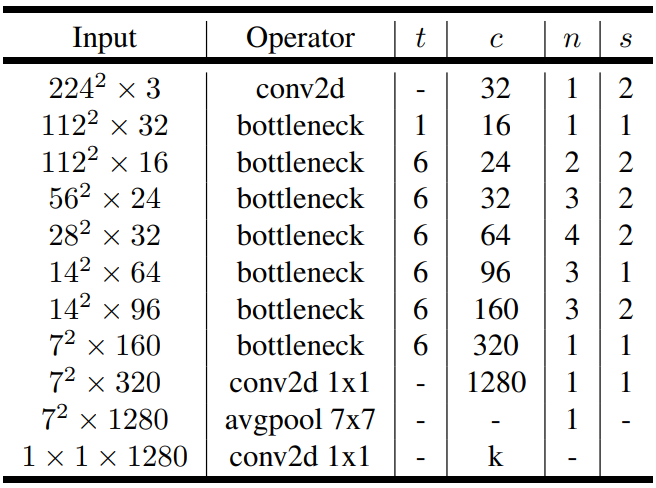
이 표에서 c는 출력 채널의 개수, n은 building block의 반복 횟수, s 는 가장 첫번째 레이어의 stride 크기(다른 레이어의 stride는 1입니다.) t는 expansion factor 입니다.
저나는 non-Linearlity로 ReLU6를 골랐습니다. ReLU6는 값이 0보다 작을때 0을, 0과 6 사이 일 때는 입력값 그대로를 출력하고, x가 6보다 클때는 6을 출력합니다.
Implementation Notes
Memory efficient inference
대부분의 machine learning platform에서 인공신경망 구현은 directed acyclic compute hypergraph G를 만드는 것입니다. Graph G에서 edge는 operation을 의미하고 node는 중간연산의 tensor를 의미합니다. 이 그래프를 통해서 memory 사용량을 아래와 같이 계산 할 수 있습니다.
여기서 연산 사이에 있는 tensor이고 이는 연산
인 node로 연결이 되어 있습니다. Tensor의 크기는
이고 연산을 위한 Kernel의 크기는
입니다.
MobileNetV2에서 Residual Connection(identity Skip Connection)을 제외한 다른 연결 구조는 없음으로, 이 인공신경망을 구성하는데 필요한 memory의 크기는 입력값의 크기, 출력값의 크기와 연산을 위한 kernel tensor의 크기를 더한 값입니다. 이는 아래의 수식에서 잘 표현되어 있습니다.
Bottleneck Residual Block
MobileNetV2의 구조는 위의 이미지와도 같습니다. 위의 구조의 operation은 다음과 같은 식으로 표현할수 있습니다.
여기서 A와 B는 linear transformation을 N은 non-linear per-channel transformation을 의미합니다. . 이 상황에서
연산을 하는 데 필요한 memory의 량은 최소
입니다. 이 수식에서 s는 입력 tensor의 한 변을 s’는 출력 tensor의 한변을. k는 입력 channel의 크기를 k’은 출력 tensor의 크기를 의미합니다.
위의 식으로 부터, inner tensor 는 t개의 n/t크기의 tensor들을 합친것을 표현됩니다. 이는 아래와 같은 수식으로 표현할수 있습니다.
이 수식을 이용하면, n=t 일때, 한번에 하나의 channel을 연산하는 것을 의미합니다. 이때 memory에 하나의 channel만 넣어도 가능함으로, memory를 많이 절약할수 있습니다.
하지만 이 방법을 사용해서 memory를 절약을 가능하게 해주는 두가지 제약사항이 있습니다.
- inner transformation(non-linearlity와 depthwise 연산을 모두 포함한)은 per-channel연산입니다.
- 이후의 non-per-channel 변환은 출력 channel의 수가 입력 channel의 수보다 훨씬 작기 때문입니다.
T의 크기를 변화시키는 것에 전체적인 연산량은 변화하지 않습니다. 하지만 연산을 하는데 걸리는 시간은 t의 크기에 따라서 변화합니다. 그 이유는 t가 너무 작으면 cache miss가 발생하여 연산 시간이 증가하기 때문입니다. 그럼으로 t가 2와 5 사이의 값을 사용하는 것이 memory 사용량과 효율적인 연산시간의 절충안이 됩니다.
Experiments
ImageNet Classification
Training setup
이 인공신경망 model은 Tensorflow를 활용해서 훈련되었습니다. Optimizer는 RMSPropOptimizer를 사용했습니다. 이때 decay와 momentum은 0.9를 사용했습니다. Batch normalization은 모든 layer의 뒤에 사용되었으며, weight decay는 0.00004가 사용되었습니다. Learning rate는 최초에 0.045가 사용되었고, 하나의 epoch 가 지나갈때 마다 0.98을 곱해주었습ㅂ니다. 훈련에는 16개의 GPU를 사용했고, batch의 크기는 96개였습니다.
Result
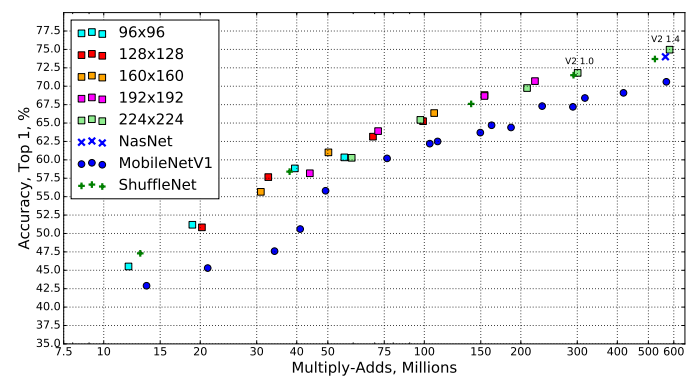
위의 그래프는 MobileNetV2, MobileNetV1, ShuffleNet, NasNet을 사용했을 때 얻을 수 있는 다양한 결과를 나타낸 것입니다. 이때 resolution multiplier로 0.35, 0.5, 0.75, 1를 사용한 것입니다. MobileNetV2에서는 1.4를 추가적으로 사용해서 더 좋은 결과를 얻었습니다.
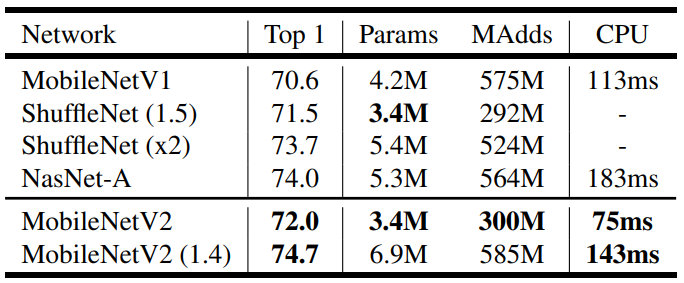
위의 표는 그래프에서 선택된 모델을 나타낸 것입니다. 여기서 모델에 사용된 parameter의 갯수와 multi-add 연산량을 알수 있습니다. 마지막 숫자는 Google Pixel 1이라는 스마트 폰에서 Tensorflow Lite를 사용했을 때의 연산 시간을 표현한 것입니다. 이때 ShuffleNet의 시간은 표현이 되지 않았는데, 그이유는 shuffling과 group convolution 알고리즘이 지원되지 않았기 때문입니다.
위의 표가 의미하는 바는, MobileNetV2가 MobileNetV1보다 정확도도 높고 연산시간도 빠른 것을 확인할수 있습니다. 또한 NasNet-A와 MobileNetV2(1.4)를 비교하면, MobileNetV2(1.4)가 더 높은 정확도를 가지고 있음과 동시 대략 30%정도 빠른 것을 확인 할 수 있습니다.
Object Detection
SSD Lite
이 논문에서 mobile에 더 최적화된 SSD의 새로운 버전을 소개합니다. SSD Lite라고도 불리우는 이 모델은 SSD의 예측 레이어의 일반적인 convolution 연산을 모두 separable convolution(depthwise 후에 pointwise)연산으로 바꾼 것입니다.
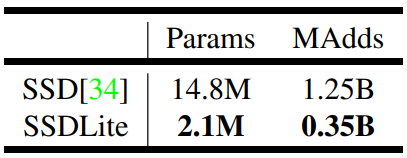
MobileNetV2를 기반으로 80개의 class를 예측하는 SSD와 SSDLite의 크기와 연산량을 비교해보면, SSDLite가 대략 7배 정도 적은 parameter 수를 가지고 있고 연산량도 4배 적은 것을 확인 할 수 있습니다.
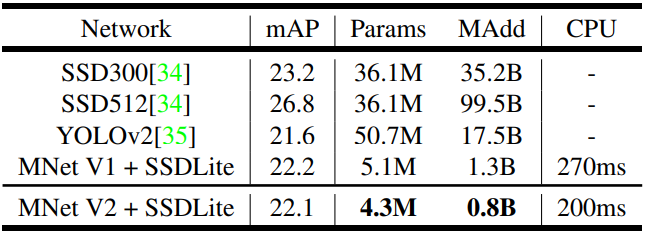
MobileNetV2와 SSDLite를 동시에 사용 하는 것이 parameter와 multi-add의 수를 많이 줄이는 것에 비해 좋은 percision을 가집니다. MobileNetV1과 비교할 경우, 비슷한 정확도를 가지고 있지만, MobileNetV2가 조금더 빠릅니다. 또한, YOLOv2와 비교할 경우, MobileNetV2가 20배 더 효율적이고, parameter 가 10배 작습니다.
Semantic Segmentation
DeepLabv3를 사용하는 MobileNetV1과 MobileNetV2를 mobile segmentic segmentation의 작업에서 비교해봅시다. DeepLabv3는 atrous convolution을 사용합니다. Atrous convolution은 계산된 feature map의 해상도를 제어하는 강력한 도구입니다. DeepLabv3는 5개의 연산 head를 가지고 있습니다. 여기에는 a) atrous spatial pyramid pooling module(three convolution with different atrous rates)와 b)
convolution head와 c) Image-level features가 있습니다.
이 논문에서는 3가지 다른 설계방법을 실험했습니다.
- 다양한 feature extractor
- 빠른 연산을 위한 DeepLabv3 head의 간소화
- performance boosting을 위한 다양한 inference 전략
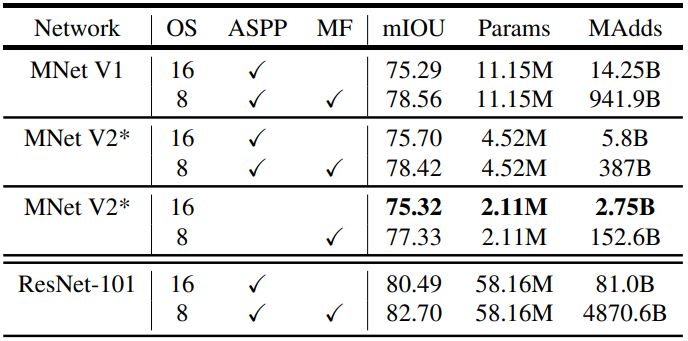 MNetV2* Second last feature map is used for DeepLabv3 head.
OS: output stride
ASPP: Atrous Spatial Pyramid Pooling
MF: Multi-scale and left-right flipped input
MNetV2* Second last feature map is used for DeepLabv3 head.
OS: output stride
ASPP: Atrous Spatial Pyramid Pooling
MF: Multi-scale and left-right flipped input
위의 표를 분석해 본 결과:
- inference 전략을 사용할 경우 multi-add computation의 수가 기하급수적으로 증가합니다. 이는 multi-scale input과 left-right flip에도 포함하는 것입니다. 연산량이 배수로 증가함으로 이는 기기안에 포함하기에는 좋은 전략이 아닙니다.
를 사용하는 것이
를 사용하는 것보다 더 효율적입니다.
- MobileNetV1을 사용하는 것이 ResNet-101를 사용하는 것과 비교해 5에서 6배 더 효율적입니다.
- DeepLabv3를 MobileNetV2의 마지막에서 두번째 feature map에 적용하는 것이 마지막 featuremap 에 적용하는 것보더 더 효율적입니다.
- DeepLabv3 heads는 연산복잡도가 높습니다. ASPP module을 제거하는 것이 조금의 성능희생으로 multi-add 연산 수를 많이 줄일 수 있습니다.
Reference
Hongl tistory 1 Hongl tistory 2