Feature Space Optimization for Semantic Video Segmentation
일반적인 시각 정보는 비디오이다. 비디오 안에는 두가지 종류의 정보가 존재합니다. 공간적인 정보와 시간적인 정보입니다. 비디오에서 공간적인 정보는 하나의 프래임 안에서 찾을 수 있습니다. 시간적인 정보는 여러가지 프래임을 통해서 얻을 수 있습니다.
Introduction
Long-range temporal regularization은 카메라와 카메라에 담겨져 있는 장면 모두 이동하기때문에 어렵습니다. Feature space에 시간축을 더하는 간단한 방법은 공간과 시간에 대한 잘못된 연관성을 만들고, 이는 카메라와 물체의 움직임에 대한 잘못된 해석을 유발합니다. 이러한 움직임은 시각적인 흐름에 지대한 영향을 미칩니다. Long-range temporal regularization is difficult because both the camera and the scene are in motion. Simply appending the time dimensions to the feature space can lead to incorrect associations and cause misinterpretation in the presence of camera and object motion. These motion cans cause significant optimal flow in the visual field.
시간축을 더하는 방법으로 사용한 Temporal regularization의 근본적인 문제점은 비디오의 시공간적 정보에서 Euclidean distance는 유사성/관련성을 찾기위한 좋은 예측을 하지 못합니다. 이 논문에서 표현한 해결방안은 Dense CRF를 사용해서 Feature Space를 최적화 하는 것입니다.
Model
모델은 클리크의 집합으로 이루어져있습니다. 이 집합은 비디오에서 서로 중복되는 block을 포함합니다.
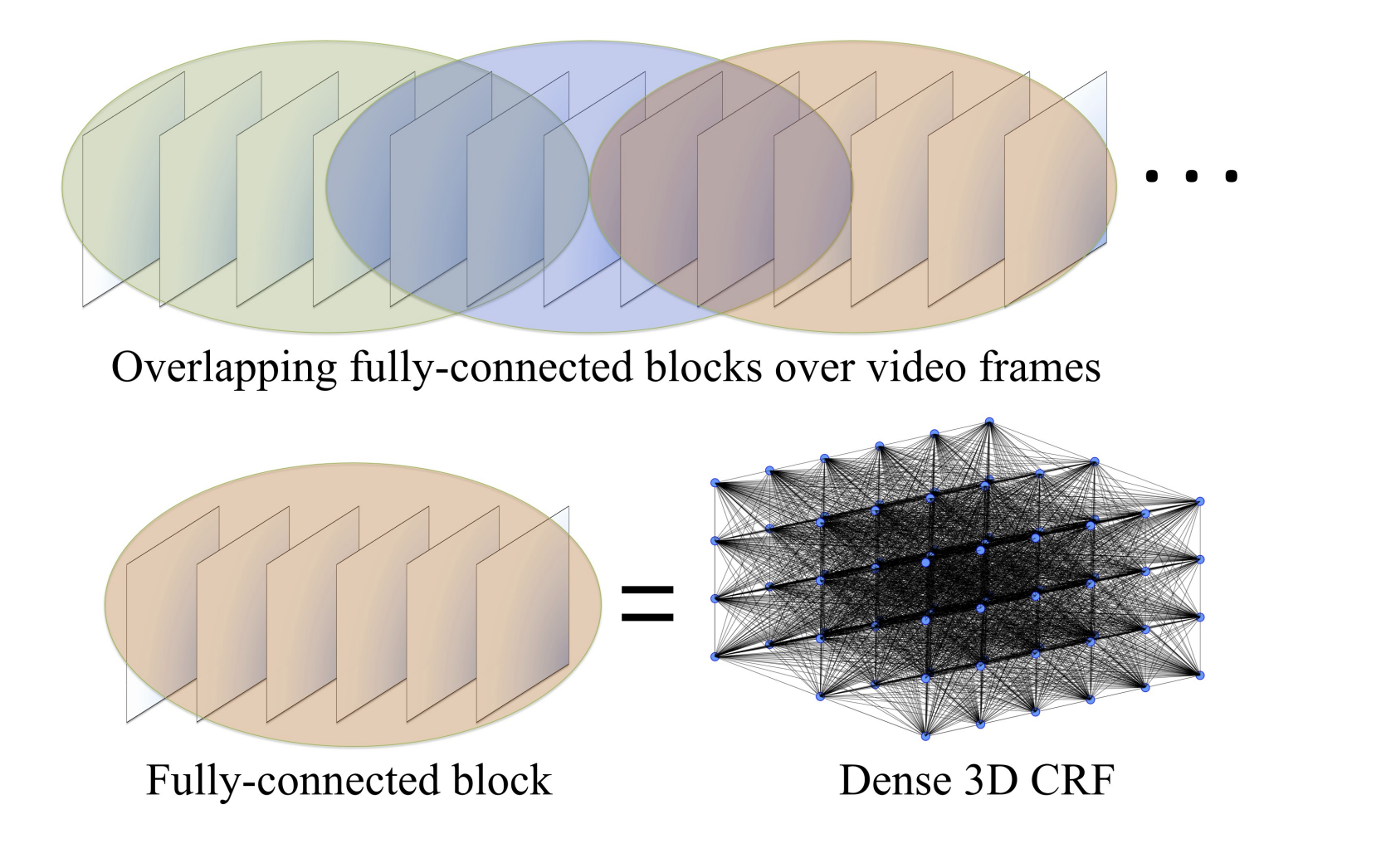
위 이미지에서처럼, 비디오는 중복되는 블락들로 덮여져 있습니다. Dense CRF는 각 블락에서 정의 되어 있습니다. Feature Space Optimization은 각 블락 안에서 이루어집니다. Structured prediction은 여러 블락에서 활용됩니다.
비디오에서 각 픽섹은 라는 백터로 표현됩니다. 여기서 b는 블락 숫자, t는 블락 b 안에 있는 프래임 숫자, i는 프래임에서 표현되는 pixel의 index를 의미합니다. Pixel p의 색 데이터는
으로 표현되고, pixel P의 좌표는
로 표현된다. P 는 비디오 내의 pixel들의 집합이라고 정의한다.
| Pixel p가 주어졌을때, |
P)})과 그와 연관되어 있는 Gibbs Energy })로 나타낼수 있다. |
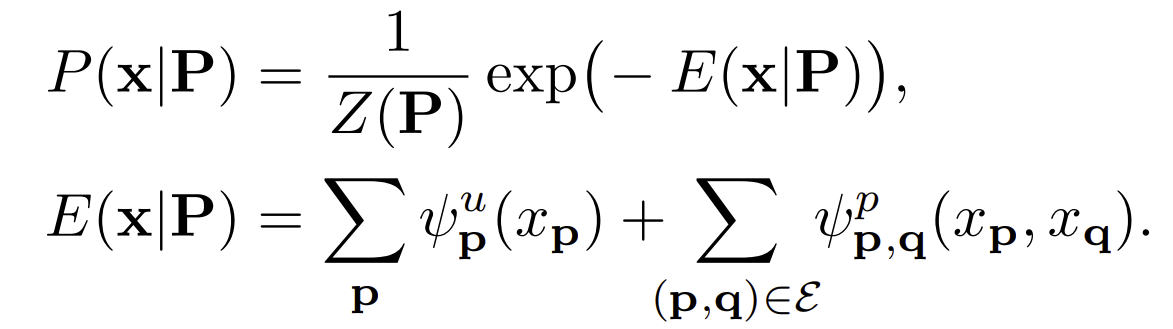
| 여기서 }=\sum_{x}\exp(-E\mathbf{(x | P)}))는 partition function이고 |
Gibbs Energy에서 가장 첫번째 항은 pixel에 Label 값을 할당하는 값이다. 두 번째 항은 두 개의 픽셀 값을 비교하여 동일하지 않는 label에 penalty를 줍니다. 이러한 값들은 Gaussian Kenral을 이용해서 정의할 수 있습니다.
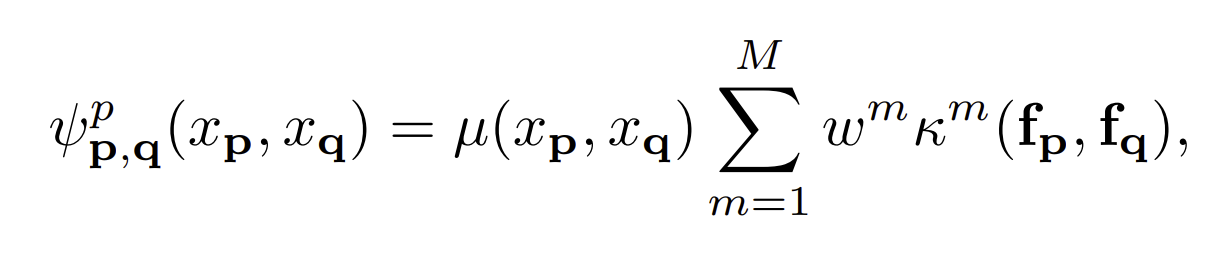
여기서 첫번째 항은 label compatibility term이고 w는 mixture weights을 의미합니다. f는 pixel p and q픽셀 값이다. 각각의 Kernel은 아래와 같이 정의할 수 있습니다.
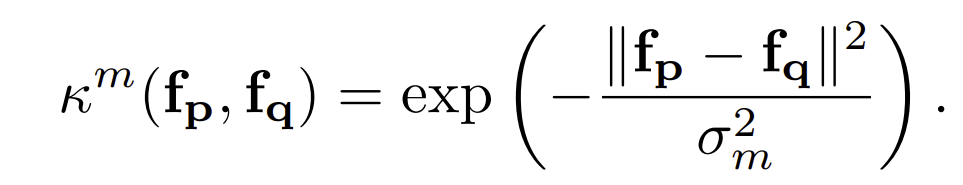
하나의 픽셀이 정의될때, feature는 D-dimensional 백터로 나타넬수 있습니다. 일반적인 Feature space는 six-dimensional로 시간, 색, 그리고 위치정보입니다:
Feature Space Optimization
Feature sensitive model을 시공간적인 비디오에 적용하는 것에 가장 어려운점은 카메라와 물체가 도시에 움직인다는 점입니다. 이 때문에 각 프레임에서 대응하는 픽셀이 많이 떨어지기도 합니다. 이때 기본적인 six-dimensional feature space는 시공간적인 관계성을 표현하는데 적합하지 않습니다.
이 논문의 접근방식은 관련된 두 점사이의 Euclidean distance를 최적화 하기위해서 feature space의 subspace를 최적화 했습니다. 이에 는
로 교체되었습니다.
블락 b가 라고 가정합시다. T는 블락내의 프래임 수로 정의하고 N을 각 프래임안에 존재하는 pixel의 갯수로 정의합시다. 그럼 optimization objective는 아래와 같이 정의됩니다.
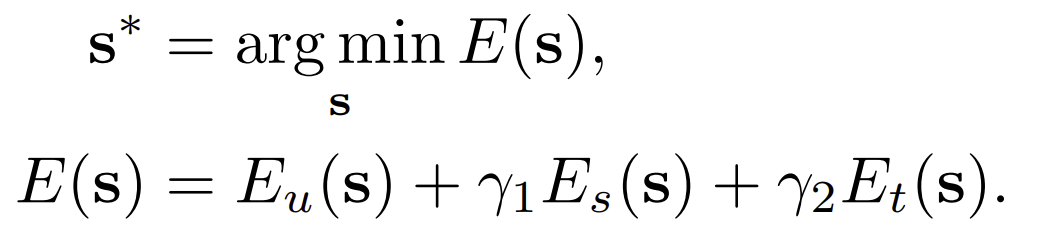
s는 block의 위치정보이고, and s* 는 최적화되어 있는 값입니다.
Data Term
Data term은 feature space가 regularization으로 인해 다른 방향으로 움직이는 것을 방해하는 목적으로 있습니다. 여기서 가장 중앙 프래임을 기준점으로 잡습니다. 기준점은 번째 프래임이 되도록 합니다. 여기서
는 a번째 프래임에 있는 pixel의 집합으로 정의합시다.
Data term은 anchor frame에 있는 point가 그들의 원래 위치에서 움직이지 못하도록 고정하는 것입니다.
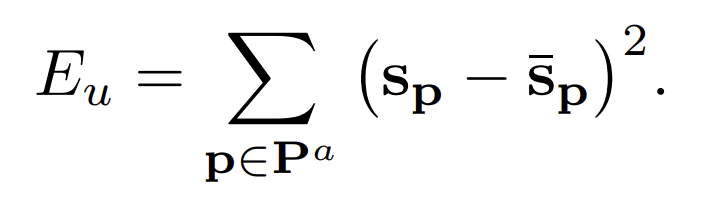
여기서 는 변하지 않은 anchor의 위치를 의미합니다.
Spatial regularization term
Spatial regularizer는 color boundaries와 detected contours에 대한 정보를 유지하도록 합니다. The regularizer는 anisotropic second-order regularization를 4-connected pixel grid위에서 사용하도록 합니다..
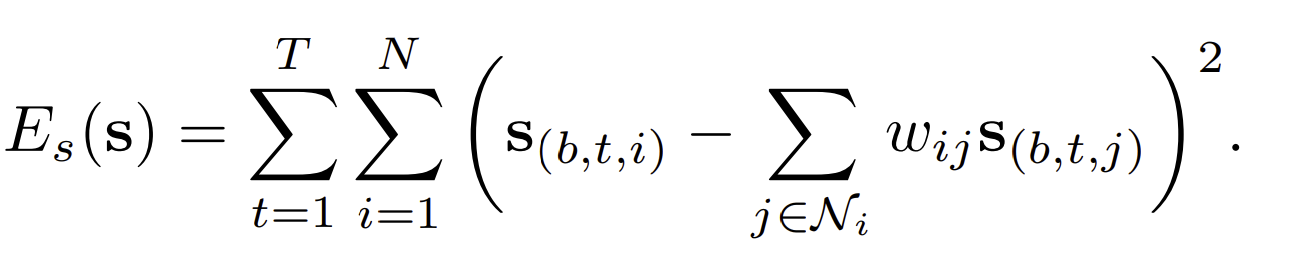
는 주변 포인트 point에 대한 집합입니다. 그리고 weight는 neihboring pixel’s value를 감소하는 효과를 줍니다.
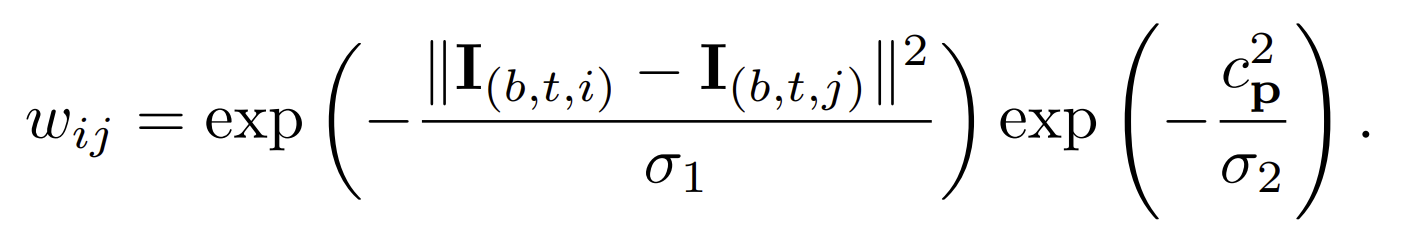
첫번째 항은 두 pixel간 색 차이를 나타냅니다. 두번째는 contour strength를 나타냅니다. Contour strengthsms structured forest를 통해서 구핬고, 그 값은 0과 1 사이입니다. Contour strength가 1 이면 pixel은 경계선에 있는 것입니다.
Temporal regularization term
Temporal regularizer는 다른 프래임에서 관련된 두개의 pixel을 예측하는 것입니다.
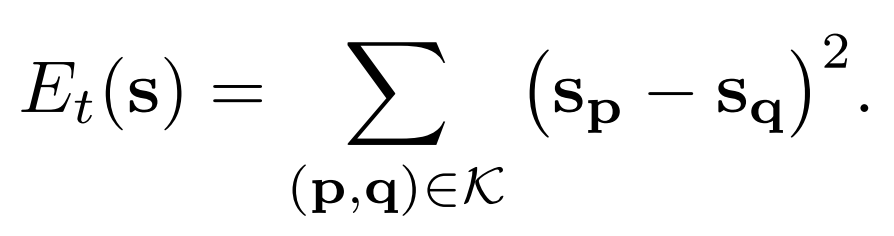
이 식은 두 개의 연관된 포인트를 최소화하는 방식으로 이루어져 있습니다. K는 연관되어 있는 두개의 포인트를 모아놓은 집합으로, p와 q값은 optical flow와 long term tracks으로 구할 수 있습니다..
Optimization
biconjugate gradient stabilized method with algebraic multigrid preconditioning으로 최적화를 실행했습니다.
Inference
Inferenece는 Krahenbuhl and Koltun가 소개한 the mean-field inference algorithm의 응용입니다 Link. The model 은 중복된 cliques로 Krahenbuhl and Koltun가 소개한 fully-connected model과는 다릅니다.
사실 분포 P를 예측하는 분포 Q를 정의합니다. 이 두 분포의 연관성은 KL-divergence로 구하게됩니다. 분포 Q는 독립된 변수로 인수분해 가능합니다. . 여기서 Q random variable의 분포로 나타납니다.. The mean-field 는 아래와 같은 수식으로 update 됩니다.
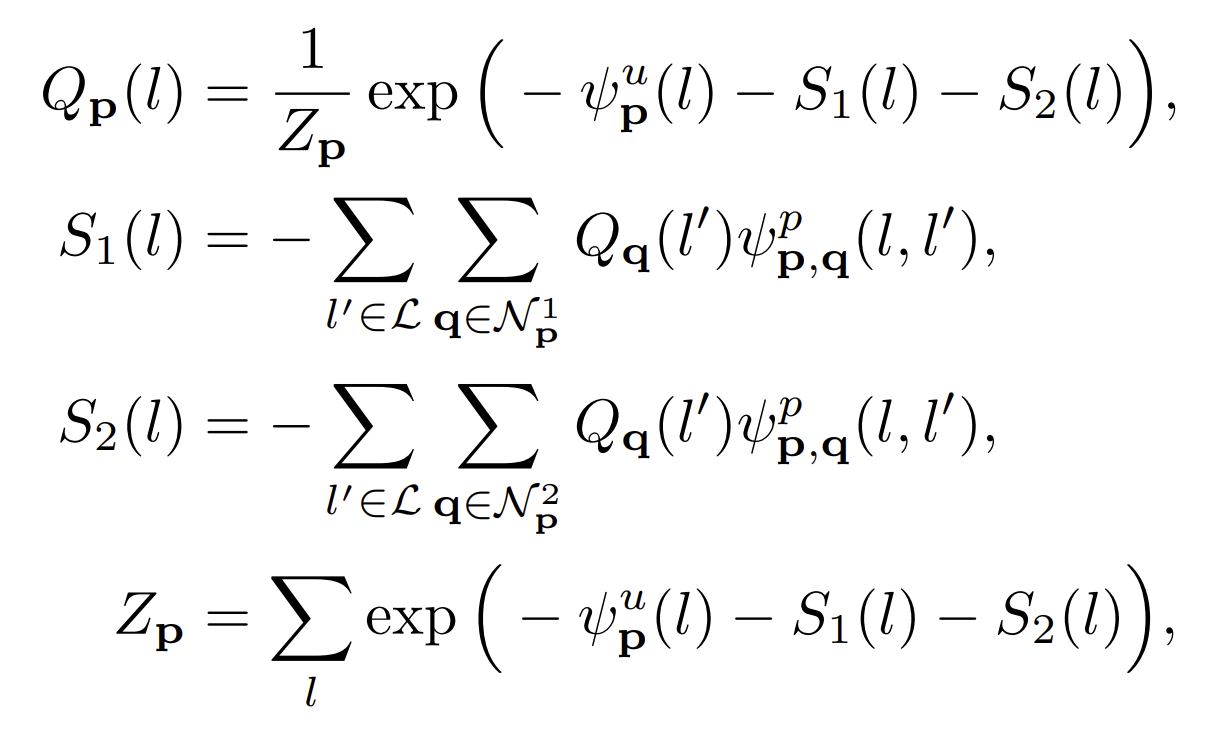
T와
는 두개의 block에서 pixel p를 둘러싼 주변 값 P의 집합입니다. Feature sapce에서 Gaussian filter를 통해서 효율적으로 update 할 수 있습니다. Labeling은
를 할 당ㅇ하는 것으로 얻을 수 있습니다.
비디오 크기가 크다면 연속된 블락으로 분리하면 됩니다. 두 개의 블락 b1과 b2가 있다고 가정하자. b1은 앞에 블락의 뒷부분을, b2는 두번째 블락의 첫번째 부분을 의미한다. 이 두개의 블락은 같은 프래임들을 가지고 있다. 여기서 Q1과 Q2는 mean-field inference로 만들어진 분포이다. 이 분포는 각각 b1과 b2가 속해있는 거대한 동영상에서 구한 값입니다. 그럼 [t1,t2]를 중복되는 프래임들이라고 설정하면, Qt는 [t1, t2]에 속해있는 t번째 프래임의 분포라고 가정하고, Q1,t와 Q2,t를 각각 Q1과 Q2에서 찾을 수 있는 부분이라고 가정한다면, 이 두개의 변화는 linear interpolation으로 구할 수 있다.
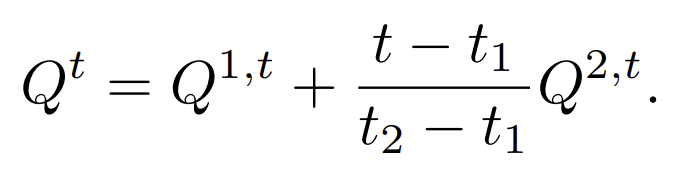
Implementation
이 논문에서, 두 개의 다른 unary potential을 사용했습니다. 첫번째는 TextonBoost를 사용했고, 두번째로는 Dilation unary라고 불리우는 CNN을 사용했습니다.Link.
모든 실험에서 optimal flow는 LDOF를 이용해서 계산했다. Discrete Flow를 이용한 Controlled experiment는 input flow의 영향을 확인하기 위해서 사용되었다. Long term trak은 Sundaram과 다른 저자들이 이야기한 방식을 사용했다. CRF 값은 grid search를 통해서 최적화를 했다.
비디오의 크기는 long-term track을 사용해서 결정되었다. 가장 첫프래임에 존재하는 포인트의 반이 사라지면, 새로운 블락을 생성했다.