Attention is all you need
Introduction
RNN, LSTM, GRNN은 sequence modeling과 transduction problem을 해결하는 State of the art 프로그램이다.
Recurrent model 들은 input과 output sequence에 있는 symbol의 위치에 따라서 순차적으로 계산을 합니다.RNN은 hidden state, ht을 순차적으로 생성합니다. 이때 ht는 h_t-1과 입력값의 position t의 함수입니다. RNN은 이전 time step의 결과값이 나올때까지 시간이 필요합니다. 그렇기에 순차적인 연산으로 훈련을 하는데 시간이 더 오래걸립니다. 이러한 시간을 줄이는 여러가지 방식들이 나와 있지만, 순차적인 연산을 해야한다는 사실은 변하지 않습니다.
Background
순차적인 연산을 병렬 연산으로 바꾸기 위해서는, 입력받은 신호들을 특별한 연산을 사용하여 연관을 지어주어야 합니다. ConvS2S의 경우에는 두 입력값 사이의 거리에 선형적으로 비례하여 연산량이 늘어납니다. ByteNet의 경우에는 Lograithmic 하게 증가합니다. 하지만 Transformer model의 경우에는 연산량이 항상 일정한 상수 값을 가지고 있습니다. 하지만 동일한 연산을 사용함으로 Effective resolution이 줄어들었습니다.
Self-Attention, 다른말로 Intra-attention, 은 하나의 시퀀스 내에서 다른 포지션을 연관 짓는 attention mechanism입니다. 이러한 방식을 사용함으로 하나의 문장안에 있는 여러가지 단어의 상관관계를 알 수 있습니다.
End-to-End memory network은 recurrent attention mechanism을 기반으로 사용됩니다,
Model Architecture.
경쟁력있는 neural sequence model의 경우에는 대부분 encoder-decoder structure를 가지고 있습니다. 그렇기에 이 논문에서도 encoder-decoder 형식을 따릅니다. Transformer는 stacked self-attention과 pointwise fully connected layer를 encode와 decoder모두에 사용합니다.
Encoder and Decoder Stacks
Encoder
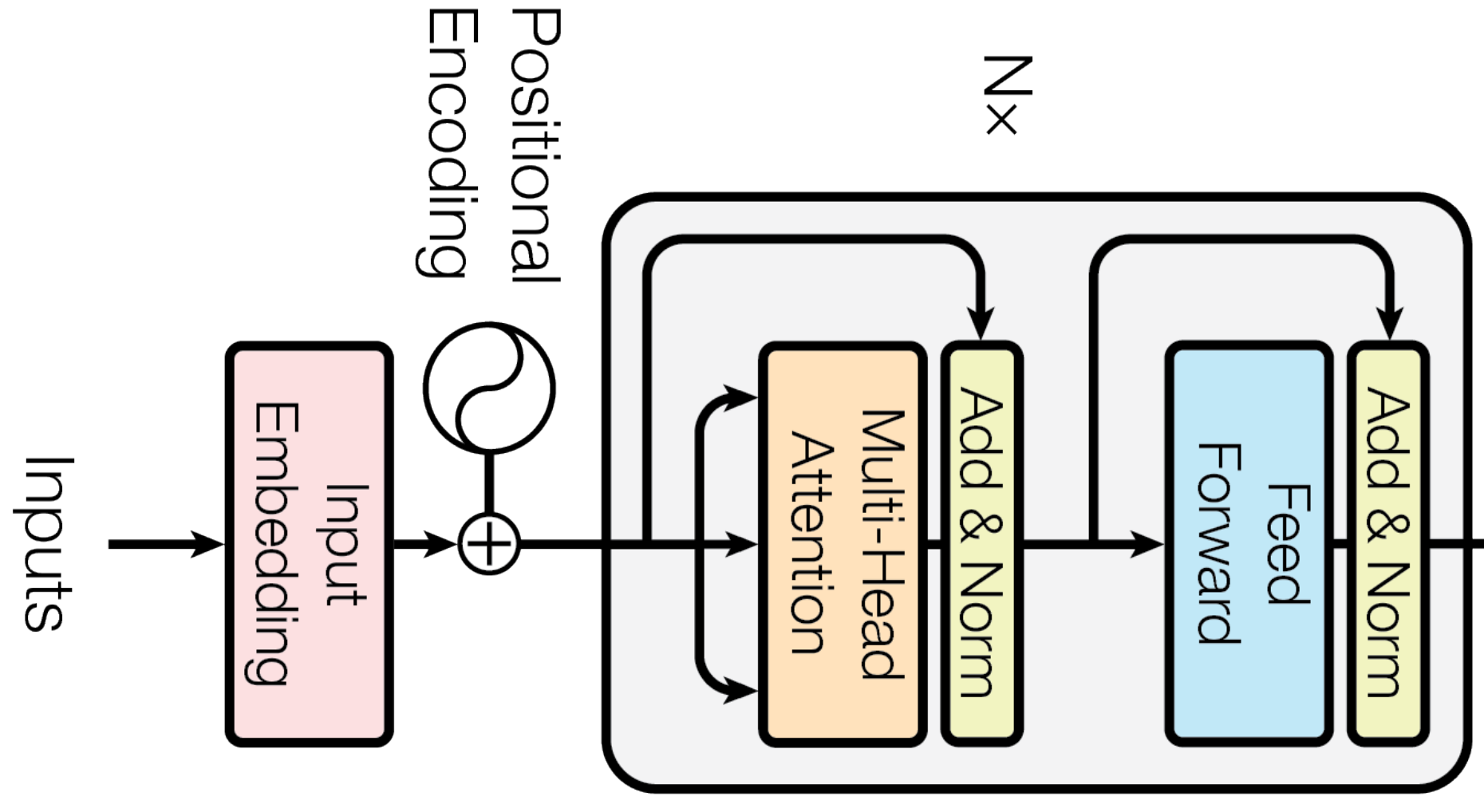
Encoder는 6개의 동일한 래이어로 이루어져있습니다. 각각의 layer는 두개의 sublayer로 이루어져있습니다. 하나는 multi-head attention이고 다른 하나는 position-wise fully connected layer입니다. 각각의 sublayer의 연산이 끝이 나면 residual connection을 활용합니다. Input과 output dimension은 512입니다.
Decoder
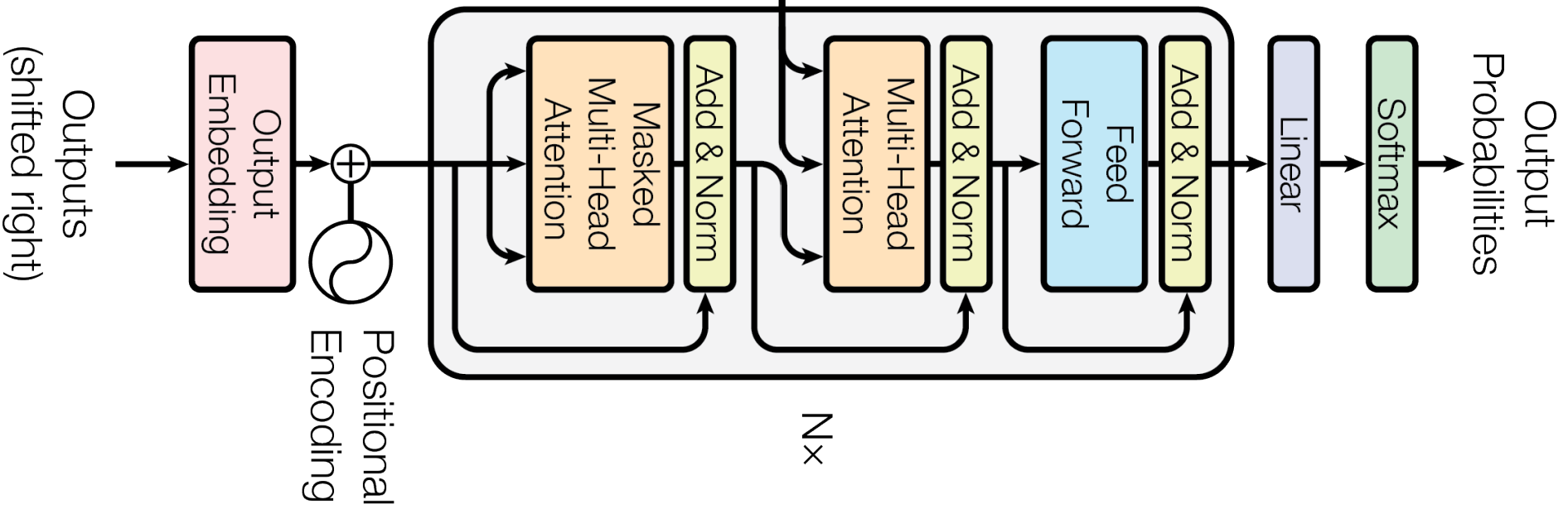
Decoder 또한 encoder와 비슷하게 6개의 Stack으로 이루어졌습니다. 또한 multi-head attention을 가장 처음사용하는 것도 비슷합니다. 두번째 레이어의 경우에는 output과 input을 합쳐 하나로 만듭니다. 이때 output은 query에 들어가고, input은 나머지 key와 value에 들어갑니다. 이후에 positionwise fullyconnected layer를 사용합니다.
Attention
Attention은 query와 key-value pair를 출력값에 mapping합니다. Output은 value의 weighted sum을 연산하는 것입니다. 여기서 weight은 query와 key의 compatibility function을 통해서 구할 수 있습니다.
Scaled Dot-Product Attention
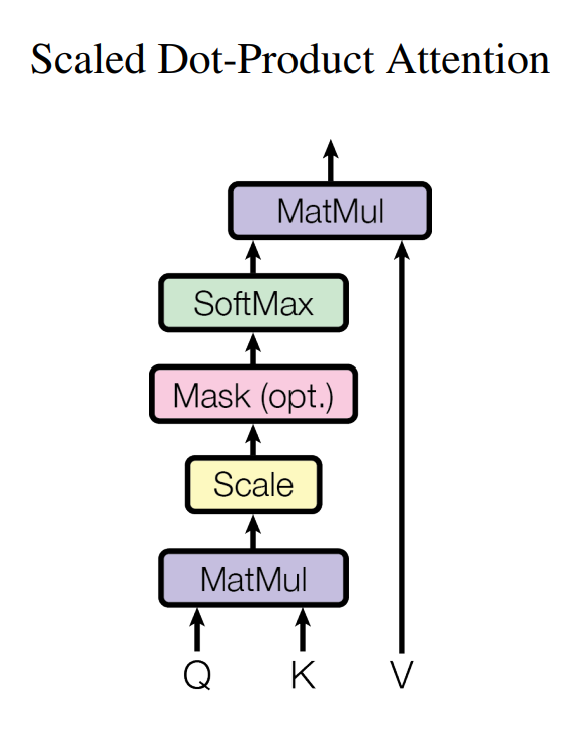
입력값은 Query(Q), Key(K), Value(V)로 구할 수 있습니다.
첫번째로는 query와 key 사이의 dot product를 구합니다. Scale은 key의 dimension의 루트값으로 나누어 주는 방식으로 사용했습니다. Softmax값을 사용해서 weight을 구해줍니다. 마지막으로 mask는 decoder에서 정보를 제한할때 사용합니다.
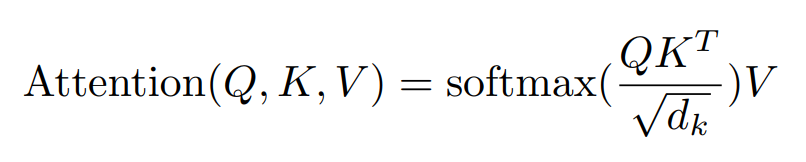
Multi-Head Attention
전체 dimenstion에 하나의 attention function을 사용하는 것이 아니라 h개의 다른 함수를 사용해서 연속되게 사용하는 방식이 더 좋습니다.
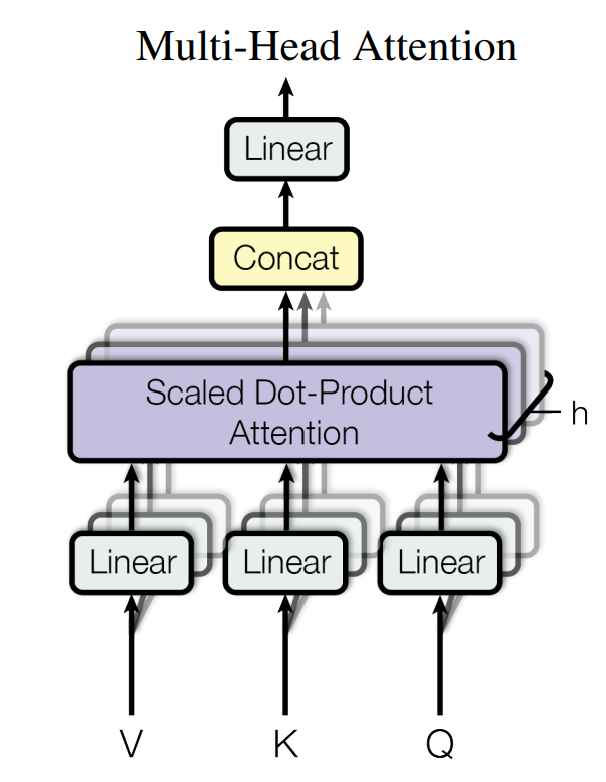
위에서 본것 처럼 Scaled Dot-Project attention아 병렬로 처리되고 난다음에, concatenation을 통해서 하나로 만들고 그 후에 다시한번 linearly project를 합니다.

여기서 h=8를 사용하고 각각의 dimension은 d_model / h = 512 = 64로 연산할 수 있습니다.
Application of Attention in our Model.
Transformer는 multi-head attention을 세가지 방식으로 사용합니다
- Query는 이전 decoder layer에서 가지고 오고, key 와 value는 encoder의 출력값을 사용합니다.
- Encoder는 self-attention layer를 가지고 있습니다. self-attention layer는 모든 값은 동일한 값을 사용합니다. 여기서는 Encoder의 previous layer에서 가지고 옵니다.
- Decoder의 self-attention layer는 현재의 정보과 자신앞에 있는 단어들의 정보들만 가지고 있어야 합니다. 그렇기에 leftward information flow를 막기위헤서 Masking이 사용됩니다. masking은 그 값을 -inf로 설정합니다.
Position-wise Feed-Forward Networks
Encoder와 decoder에서는 Fully connected feed-forward network를 가지고 있습니다. 이 network는 두개의 레이어로 이루어져있습니다. 그리고 첫번째 레이어와 두번째 레이어 사이에는 ReLU activation을 사용합니다. Input과 output의 dimension은 512이고 inner layer의 dimension은 2048입니다.
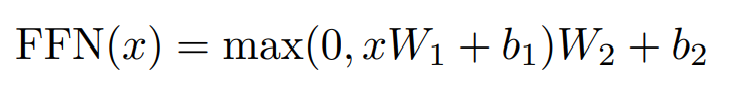
Embedding and Softmax.
각 model은 Learned embedding을 사용해서 input과 output을 dimension이 d인 vector로 변환합니다. Encoder와 Decoder의 embedding layer는 같은 weight를 사용합니다. 또한, pre-softmax linear transformation 또한 같은 weight를 사용합니다.
Positional Encoding
모든 입력값을 한번에 처리하기 위해서 각각의 input에 대하여 positional information을 사용해야합니다. 이는 sequenctial 한 정보를 가지고 있다고 가정하기 때문이며, 이때 positional encoding을 사요합니다.
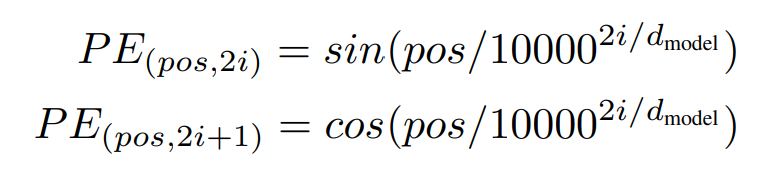
Why self-Attention
Self-attention을 사용하는 세가지 이유가 있습니다.
- Total computational complexity per layer
- Amount of computation that can be parallelized, measured by the minimum number of sequential operation required
- The path length between long-range dependencies in the network, measured by maximum path length between two input and output positions.
