Attention is all you need
Introduction
RNN, LSTM, GRNN are state of the art approaches in sequence modeling and transduction problem.
Recurrent models computes along the symbol position of the input and output sequences. RNN generates a sequence of hidden state ht, as a funstion of ht-1 and input for position t. Since RNN needs a time to process the previous time step, it takes longer to train. Several methods were developed to have computational improvements. However, the fundamental constaints of sequential computation remains.
Background
To make the sequential computation into a parallel computation, most of the network relates signal through some operation. In case of ConvS2S, the operation linearly grows as distance between two input grows. In case of ByteNet, it grows logarithmically. In the Transformer model, the calculation takes a constant time, although effective resolution is reduced due to averaging attention-weighted positions.
Self-Attention, a.k.a. Intra-attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
End-to-End memtory network are based on recurrent attention mechanism.
Model Architecture.
Most competitive neural sequence models have an encoder-decoder structure. Thus in this paper, author uses the same encoder-decoder stucture. The transformer use stacked self-attention and pointwise, fully connected layers for both encoder and decoder.
Encoder and Decoder Stacks
Encoder
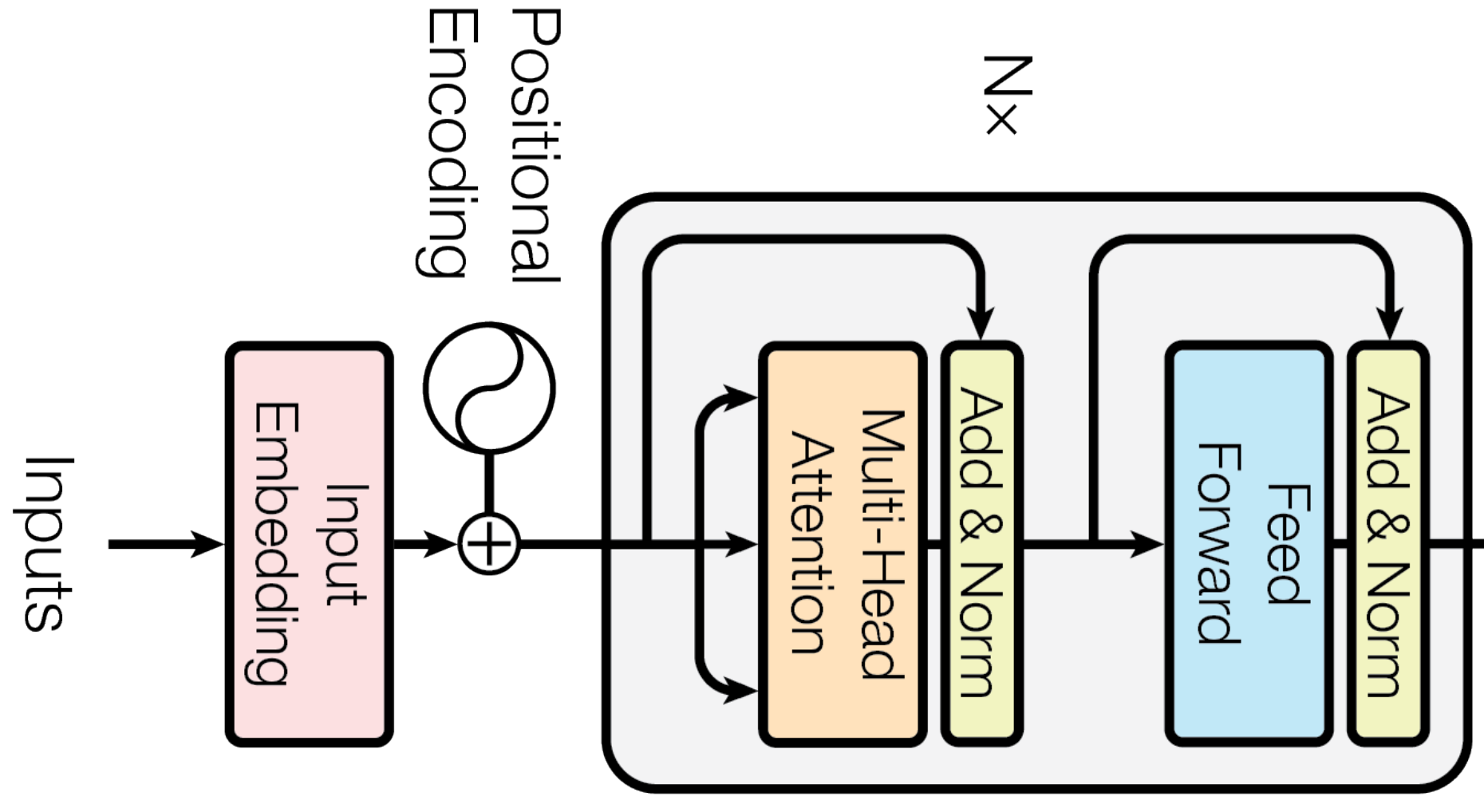
The encoder is composed of a stack of N=6 identical layers.
Each layer has two sublayer: multi-head attention and position-wise fully connected layer.
Residual connection is applyed after each sublayer.
The dimension of the output and the input is 512.
Decoder
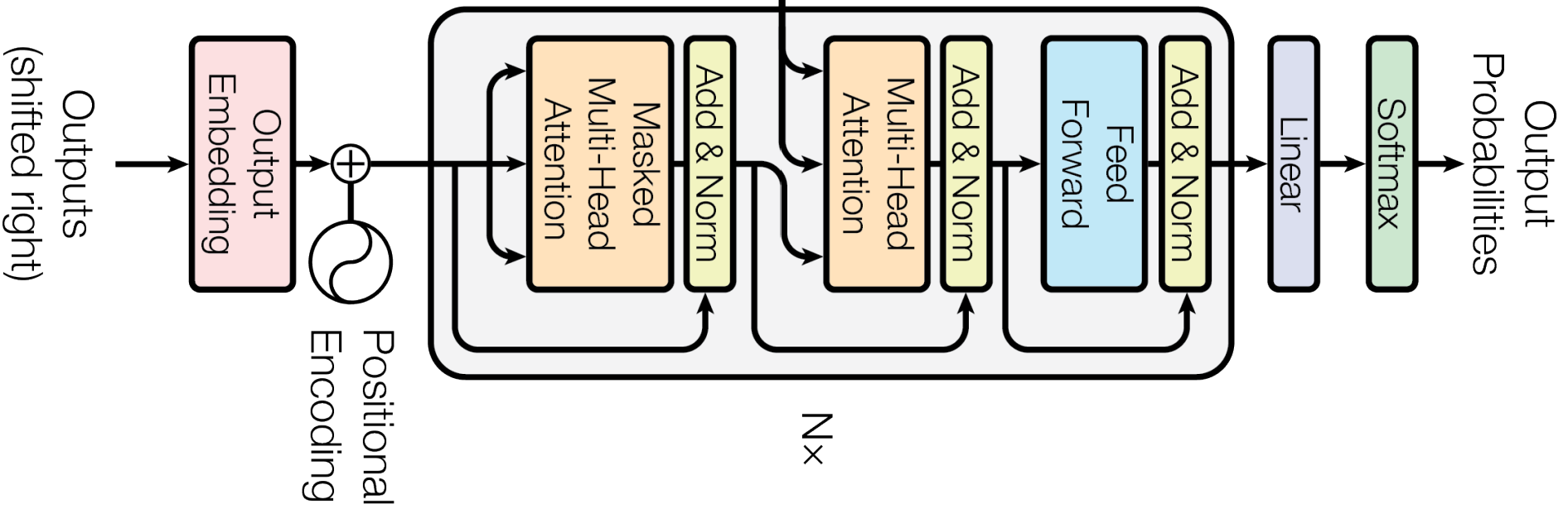
Decoder is composed of a stack of N = 6. Similar to encoder network, we have multi-head attention in the beginning of the decoder. The second layer integrates the output and input: output goes to query, input goes to key and value.
Attention
Attention faction is mapping query and a set of key-value pairs to an output. Output is computed as a weighted sum of values, where the weights assigned to each value is computed by a compatibility function of the query with the corresponding key.
Scaled Dot-Product Attention
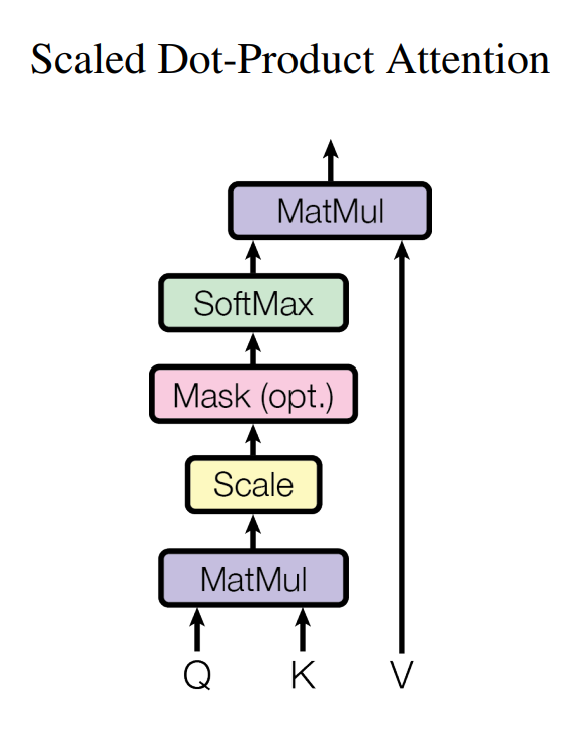
The input consist of query(Q), key(K) and value(V).
First compute the dot project of the query with all keys. Scale is done by dividing each by root of dimension of key. Then applying the softmax function to obtiona the weight on the value. The mask is used in the decoder to block the information is needed.
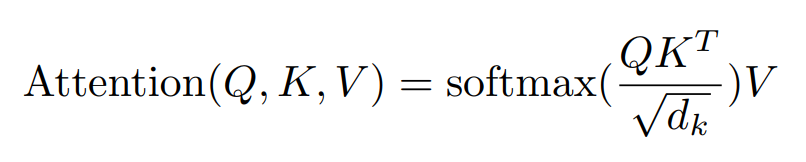
Multi-Head Attention
Instead of performing a single attention function with full dimension, it is beneficial to linearly project the queries, key and values h times with different, learned linear projection.
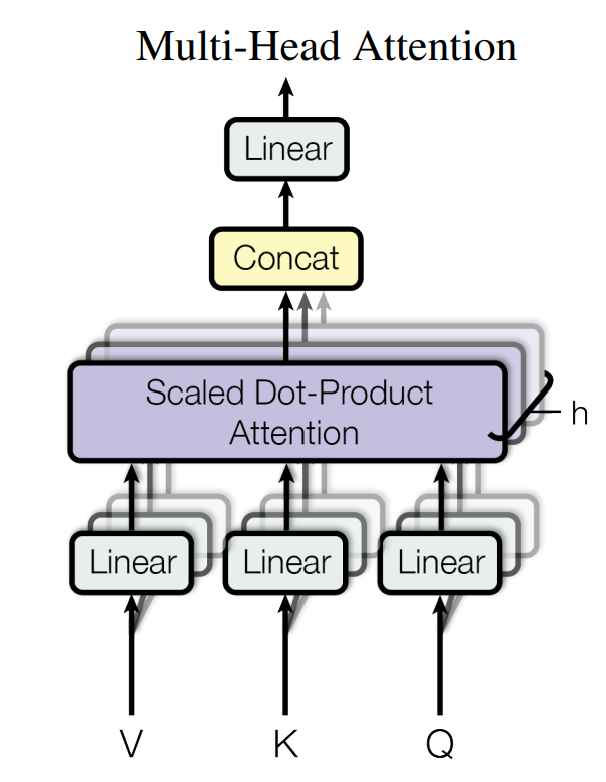
As shown in the image, after Scaled Dot-Project attention performed in parallel, these are concatenated and projected linearly.

In this work, h=8 and each dimension is d_model / h = 512/8 = 64.
Application of Attention in our Model.
The Transformer uses multi-head attention in three different ways:
- The queries come from the previous decoder layer. The memory keys and values come from the output of the encoder.
- The encoder contains self-attention layers. In a self-attention layer, all of the keys, values, and queries come from the output of the previous layer in the output.
- Self-Attention layer in the decoder allow each position in the decoder to attend to all position in the decoder up to and including that position. To prevent leftward information flow in the decoder, masking is done by setting the value to -inf.
Position-wise Feed-Forward Networks
Each of the layers in encoder and decoder contains a fully connected feed-forward network. They have two linear transformations with ReLU activation in between. Input and output is d=512 and inner layer is 2048.
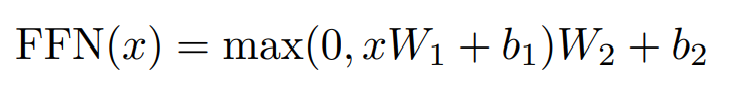
Embedding and Softmax.
The model use learned embedding to convert the input and ouput to vector of dimension d. Two embedding layers and the pre-softmax linear transformation linear transformation use same weight matrix.
Positional Encoding
Since the input token does not contain any information about position and to use the order of the sequence, they use positional encoding.
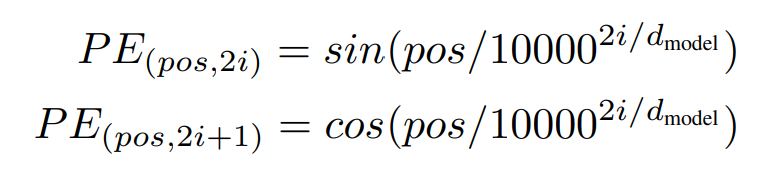
Why self-Attention
There is three desiderata that motivated to use self-attention.
- Total computational complexity per layer
- Amount of computation that can be parallelized, measured by the minimum number of sequential operation required
- The path length between long-range dependencies in the network, measured by maximum path length between two input and output positions.
